Atribución en iOS 14+: De silos a una single source of truth


Hagamos un breve viaje al pasado, al 23 de junio de 2020, cuando Apple presentó las actualizaciones de iOS 14 que cambiarían para siempre el ecosistema de las apps móviles.
Todos en el ecosistema empezaron a hacerse las mismas preguntas:
- ¿SKAdNetwork será una buena forma de medir los esfuerzos de marketing o no? (pista: ambas)
- ¿Cuáles serán las tasas de opt-in del pop-up de App Tracking Transparency (ATT)? (pista: más altas de lo esperado)
- Si la mayoría de los usuarios no hará opt-in de todos modos, ¿por qué debería molestarme en mostrar el pop-up de la ATT? (pista: porque esta muestra de usuarios ayudará a responder muchas preguntas sobre el conjunto completo de usuarios)
Por supuesto, todas las preguntas anteriores eran totalmente legítimas, pero con el tiempo quedó claro que la preocupación más crítica era en realidad:
¿Cómo puedo consolidar todas estas fuentes de datos aisladas en una single source of truth?
La realidad de esta nueva realidad es que existen múltiples realidades. Con la llegada de iOS 14, los marketers empezaron a recibir flujos de datos de muchas fuentes diferentes: SKAdNetwork, usuarios con consentimiento de la ATT, datos agregados de modelado probabilístico, insights basados en incrementalidad, APIs específicas para Apple Search Ads y más…
Pero ¿cuál de estos flujos de datos es la verdad real? ¿Cómo se supone que los marketers deben analizar todos estos datos entrantes y sentirse seguros de las decisiones que toman? Buena pregunta.
Nos complace decir que tenemos una solución para este problema crítico. Antes de entrar en eso, veamos con más detalle el problema en cuestión.
El problema
A efectos de este análisis, centrémonos en los siguientes 3 conjuntos de datos de atribución:
- SKAdNetwork: atribución realizada por iOS en el propio dispositivo
- Usuarios con consentimiento de la ATT: atribución basada en coincidencia de ID.
- Tráfico sin consentimiento: medición agregada a nivel de campaña mediante Aggregated Advanced Privacy (para medios pagos) o modelado probabilístico (para medios propios). Estos métodos generan reportes de rendimiento de campañas sin identificar dispositivos o usuarios individuales.
SKAdNetwork tiene dos ventajas significativas frente a los demás: es determinista y cubre a todos los usuarios. Sin embargo, también tiene desventajas importantes: La medición de LTV es limitada (por decirlo suavemente), no cubre todos los flujos (como mobile web), los postbacks se retrasan y existen posibles brechas de fraude, entre otras.
Por otro lado, la coincidencia de ID, aggregated advanced privacy y el modelado probabilístico tienen sus propias ventajas, pero también su propio conjunto de desventajas.
Solución propuesta: Elegir el modelo preferido según la necesidad específica.
Por qué no funcionará: En teoría: problema resuelto. En la práctica… esto no es posible. Como los datos de SKAdNetwork están anonimizados, ninguna entidad puede saber si esas mismas conversiones fueron atribuidas o no por otros modelos. Y lo mismo aplica en sentido inverso.
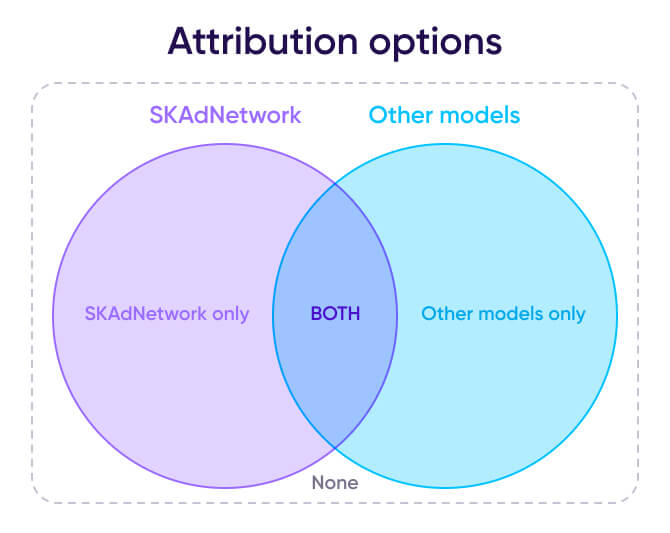
Potencialmente, cada instalación podría estar:
- Atribuida solo por SKAdNetwork
- Atribuida solo por otros modos de atribución
- Atribuida por ambos
- No atribuida por ninguno
Esta es precisamente la esencia de SKAdNetwork: la anonimización. Por diseño, evita la ingeniería inversa para hacer matching a nivel de usuario gracias a funciones como retrasos aleatorios en el envío del postback.
En la práctica, sin embargo, los anunciantes se enfrentaban a dos realidades paralelas.
La mayoría de las soluciones para la nueva era de iOS 14 se ven actualmente así:
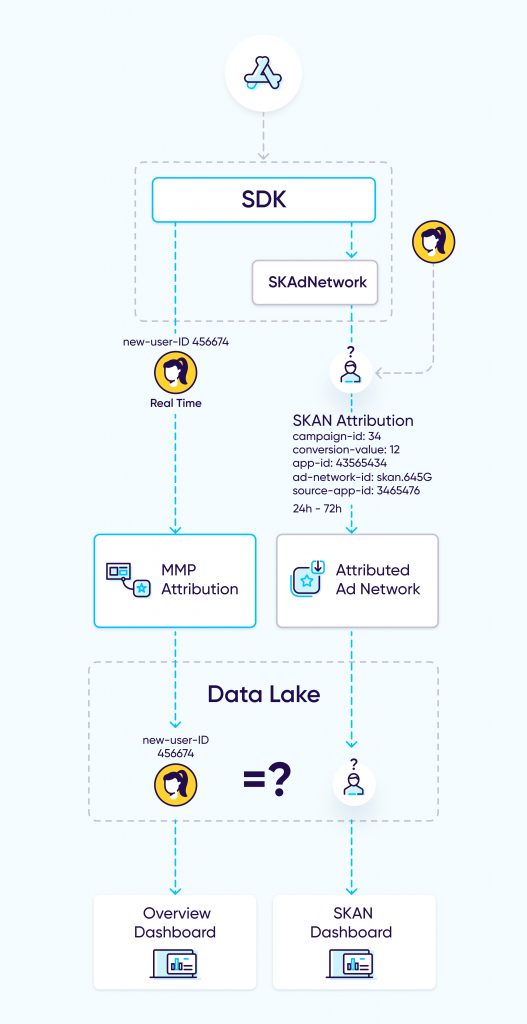
Múltiples APIs y dashboards hacen que sea casi imposible para los anunciantes obtener insights accionables. La única solución es un dashboard o API consolidado donde los datos se combinen, dedupliquen y unifiquen, todo ello preservando la privacidad del usuario y alineándose con las políticas de Apple. Sin embargo, como se explicó antes, esto no era posible.
Recibe en tu bandeja de entrada las últimas noticias de marketing e insights de expertos
Problema resuelto
SKAdNetwork tiene limitaciones, y muchas de ellas pueden superarse innovando sobre los valores de conversión del protocolo. Este caso no es la excepción.
Aprovecharemos el valor de conversión para crear una realidad unificada, una single source of truth entre las distintas fuentes de atribución.
Los valores de conversión son la única forma de que los anunciantes en iOS midan el LTV del usuario en campañas SKAN. Al mapear correctamente esos 64 valores posibles, los anunciantes pueden medir ingresos posteriores a la instalación, actividad y retención.
Nuestro reciente lanzamiento de AppsFlyer Conversion Studio ofrece a nuestros clientes un entorno de configuración hiperflexible, donde cada valor puede maximizarse y contemplarse por completo en el mapeo.
Aunque los valores de conversión limitan la capacidad del anunciante para medir el LTV (tanto en tiempo como en rango), sí ofrecen una solución para la deduplicación.
Déjame explicártelo:
- Cuando un usuario abre por primera vez una app recién descargada, AppsFlyer intenta atribuir la instalación.
- Suponiendo que AppsFlyer pueda atribuir la instalación, se utiliza un único bit del valor de conversión del SKAN para indicar una marca de “atribución encontrada” dentro del valor de conversión mediante la llamada updateConversionValue.
- Si AppsFlyer recibe más adelante un postback de SKAN, agregará los datos de la single source of truth según esta ecuación:
Usuarios atribuidos por AppsFlyer + postbacks de SKAN para los que la marca de “atribución encontrada” es falsa.
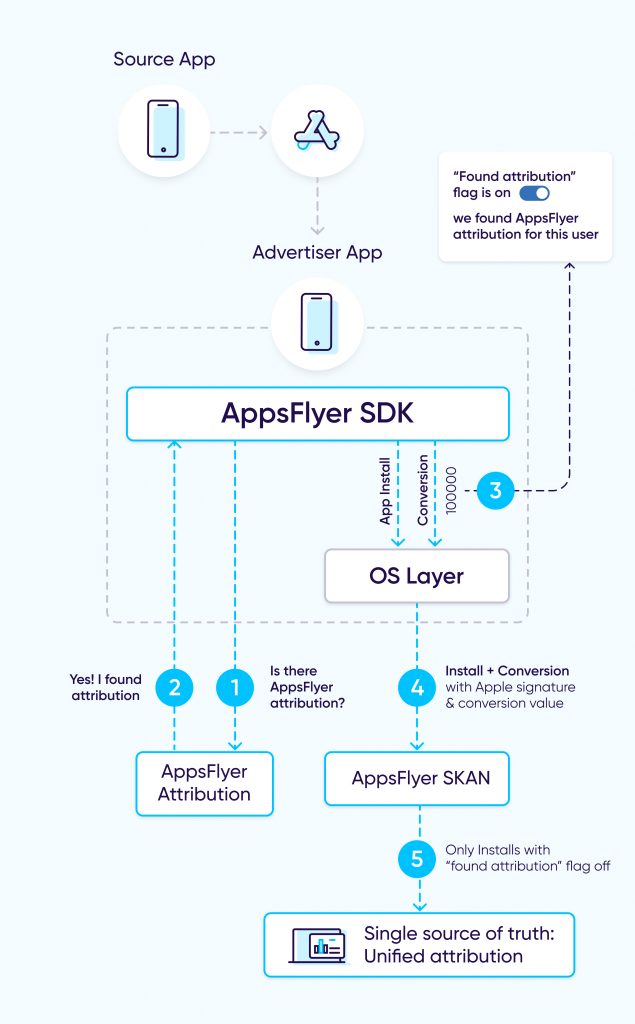
Hitos críticos en el camino hacia una single source of truth
Para que esto funcione, hay un paso importante en el proceso: los anunciantes deben dedicar parte de su valor de conversión a la deduplicación. Esta elección debe poder ser controlada por el anunciante, con la flexibilidad de activarla o desactivarla según prefiera.
En el recién lanzado Conversion Studio, donde los anunciantes pueden configurar fácilmente mapeo de valor de conversión con múltiples métricas, estamos añadiendo precisamente esta opción.
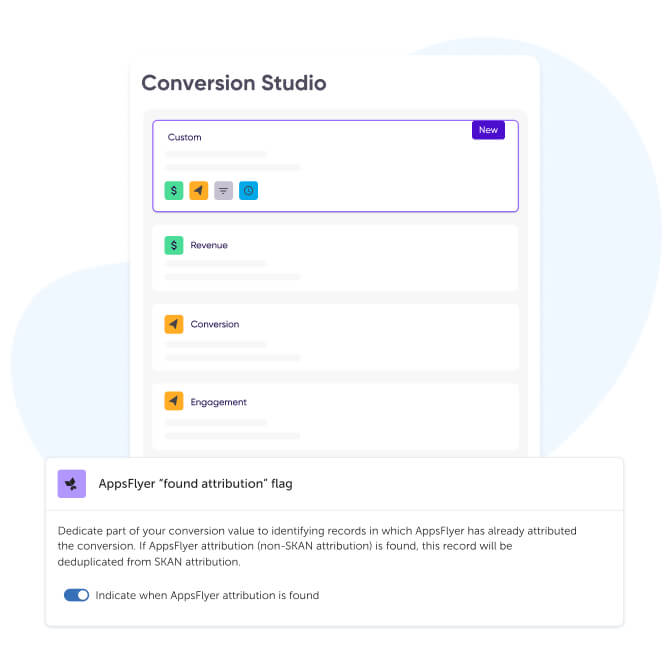
Cuando se activa, esta configuración consolidará, deduplicará y unificará los datos reportados en reportes agregados.
guía
Dentro de SKAN: insights de SKAdNetwork
Pero espera, ¿esto no vulnera la privacidad del usuario final?
En absoluto. Los datos permanecen completamente anonimizados; los umbrales, temporizadores y retrasos siguen garantizando que nadie pueda alcanzar granularidad a nivel de usuario. Todas las capas de defensa de SKAdNetwork siguen vigentes para garantizar que la privacidad del usuario final no se vea afectada en lo más mínimo.
El resultado final sigue siendo completamente agregado, sin posibilidad de desanonimizar los datos. Simplemente ayuda a deduplicar las realidades agregadas y a llegar a una single source of truth puramente agregada.
Hagamos un resumen rápido:
Ventajas
Puntos de datos aislados → Single source of truth
La fórmula es simple:
Realidades paralelas → difícil tomar decisiones
Single source of truth → insights de marketing accionables
Maximiza las ventajas de cada modelo
Una vez que los anunciantes puedan deduplicar los datos de ambos modelos agregados, podrán disfrutar de los beneficios de cada uno, por ejemplo:
- LTV completo basado en modelos tradicionales de atribución
- Cobertura total y puntos de datos deterministas de SKAdNetwork
Maximizar estas ventajas ayudará a los marketers a tomar mejores decisiones, incluso en una realidad de iOS 14+.
Sin comprometer la privacidad de los usuarios finales
El framework de privacidad de SKAdNetwork sigue vigente y sin cambios.
La optimización de campañas de SKAdNetwork sigue igual
El hecho de que los postbacks de SKAdNetwork se envíen para todos los usuarios, hayan sido o no atribuidos también en modos paralelos, garantiza que las redes puedan seguir optimizando en función de los valor de conversión del SKAN.
En definitiva: la realidad de SKAN sigue estando completamente cubierta y siendo precisa, por lo que quienes aprovechan estos datos no se ven afectados.
Desventajas
6 bits de valor de conversión → 5 bits de valor de conversión
Como se mencionó, se asignará un bit para indicar si la instalación actual también fue atribuida en un modo de atribución paralelo. Para permitir esto, el valioso recurso de los valores de conversión serán un poco más limitado (y sí, el juego de palabras es intencional).
Algunos de nuestros clientes más grandes participaron como design partners en la planificación de esta solución y estuvieron más que dispuestos a asignar un solo bit a cambio de la promesa de una single source of truth. Dicho esto, sigue siendo una decisión que debe tomar el anunciante.
Palabras finales
A medida que la industria sigue adaptándose a esta nueva era, es fundamental que la precisión de los datos y la privacidad del usuario sigan coexistiendo. En AppsFlyer, nuestra misión es empoderar a los anunciantes mientras atraviesan estos cambios.
Tener un 100% de certeza sobre los resultados reales de tus esfuerzos de marketing es crítico para la misión. Una single source of truth para el rendimiento de marketing garantiza que los marketers optimicen su gasto publicitario, hagan crecer su negocio y ofrezcan una experiencia superior a los usuarios finales.