
Attribution in iOS 14+: From silos to a single source of truth


Let’s take a quick trip down memory lane to June 23rd, 2020, when Apple introduced the iOS 14 updates that would forever change the mobile app ecosystem.
Everyone across the ecosystem began asking the same questions:
- Is SKAdNetwork going to be a good way to measure marketing efforts or not? (hint: both)
- What will the opt-in rates be for the App Tracking Transparency (ATT) pop-up? (hint: higher than expected)
- If most users won’t opt in anyway, why should I even bother showing the ATT pop-up? (hint: because this sample set of users will help answer many questions about the full set of users)
All of the above were totally legitimate questions of course, but over time it became evident that the most critical concern was actually:
How can I consolidate all of these siloed data sources into a single source of truth?
The reality of this new reality is that there are multiple realities. With the onset of iOS 14, marketers began receiving data streams from many different sources: SKAdNetwork, ATT-consented users, aggregate data from probabilistic modeling, incrementality-based insights, dedicated APIs for Apple Search Ads, and more…
But which data stream is the actual truth here? How are marketers supposed to look at all of this incoming data and feel confident in the decisions they’re making? Good question.
We’re happy to say that we’ve got a solution for this critical problem. Before we get into it, let’s take a deeper look at the issue at hand.
The problem
For the sake of this analysis, let’s focus on the following 3 sets of attribution data:
- SKAdNetwork: attribution performed by iOS, on the device itself
- ATT-consented users: attribution based on ID matching
- Non-consented traffic: aggregate campaign-level measurement through Aggregated Advanced Privacy (for paid media) or probabilistic modeling (for owned media). These methods produce campaign performance reports without identifying individual devices or users.
SKAdNetwork has two significant advantages over the others: it’s deterministic and covers all users. However, it also has major disadvantages: LTV measurement is limited (to say the least), it doesn’t cover all flows (mobile web, for instance), postbacks are delayed, and there are potential fraud loopholes, to name a few.
ID matching, aggregated advanced privacy, and probabilistic modeling on the other hand have their own advantages, but also their own set of disadvantages.
Suggested solution: Choose the preferred model based on the specific need.
Why it won’t work: In theory: problem solved. In reality…this isn’t possible. As SKAdNetwork data is anonymized, no entity can know if the same conversions were attributed by other models or not. And the same goes in reverse.
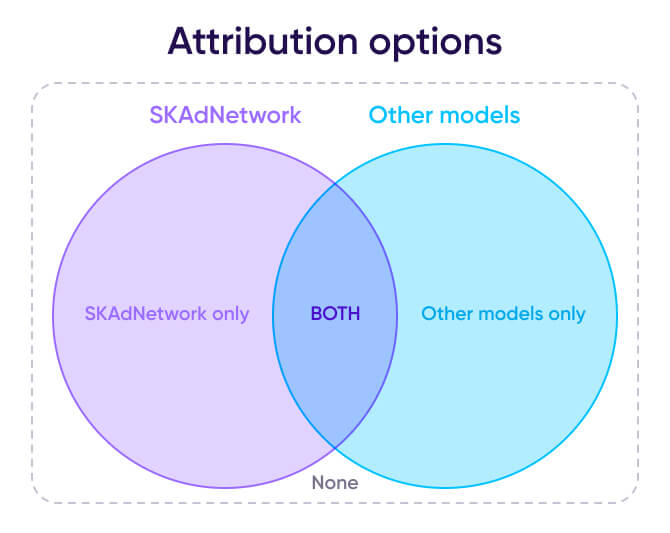
Potentially, each install could be:
- Attributed only by SKAdNetwork
- Attributed only by other attribution modes
- Attributed by both
- Attributed by none
This is the very essence of SKAdNetwork: anonymization. By design, it prevents reverse-engineering for user-level matching thanks to features such as randomized delays in firing the postback.
In reality, however, advertisers were faced with two parallel realities.
Most solutions for the new iOS 14 era currently look like this:
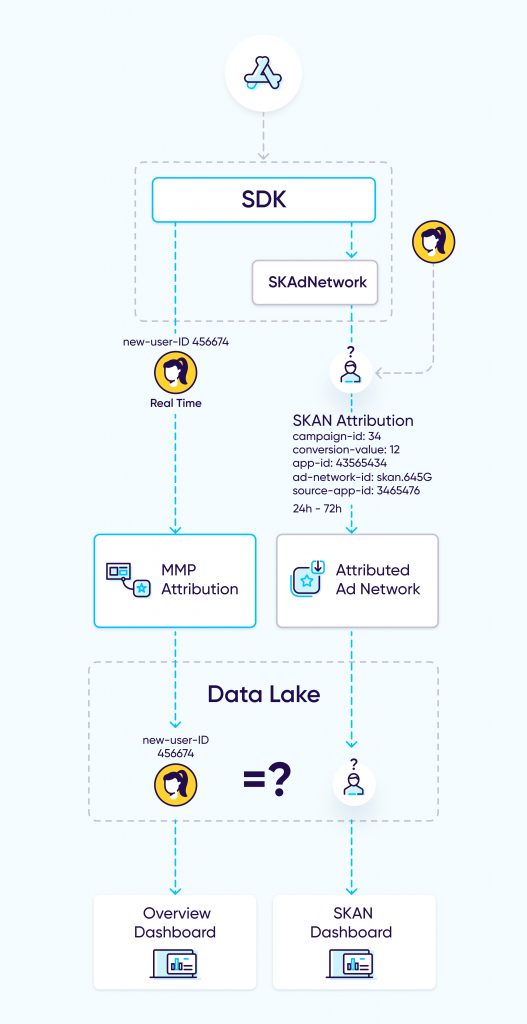
Multiple APIs and dashboards make it nearly impossible for advertisers to reach actionable insights. The only solution is a consolidated dashboard or API where the data is combined, deduplicated, and unified, all while preserving user privacy and aligning with Apple’s policies. However, as explained above – this is was not possible.
Get the latest marketing news and expert insights delivered to your inbox
Problem solved
SKAdNetwork has limitations, and many of them can be overcome by innovating on top of the protocol’s conversion values. This case is not different.
We will leverage the conversion value to create a unified reality, single source of truth across the different attribution sources.
Conversion values are the only way for iOS advertisers to measure user LTV in SKAN campaigns. By properly mapping out those 64 possible values, advertisers can measure post-install revenue, activity, and retention.
Our recent release of the AppsFlyer Conversion Studio provides our customers with a hyper-flexible configuration environment, where each value can be maximized and fully accounted for in the mapping.
While conversion values do limit the advertiser’s ability to measure LTV (both in time and range), they do offer up a solution for deduplication.
Let me walk you through it:
- When a user launches a newly-downloaded app for the first time, AppsFlyer attempts to attribute the install.
- Assuming AppsFlyer can attribute the install, a single bit from the SKAN conversion value is utilized to indicate a “found attribution” flag in the conversion value via the updateConversionValue call.
- If a SKAN postback is received by AppsFlyer later on, AppsFlyer aggregates the single-source-of-truth data according to this equation:
AppsFlyer attributed users + SKAN postbacks for which the ‘found attribution’ flag is false.
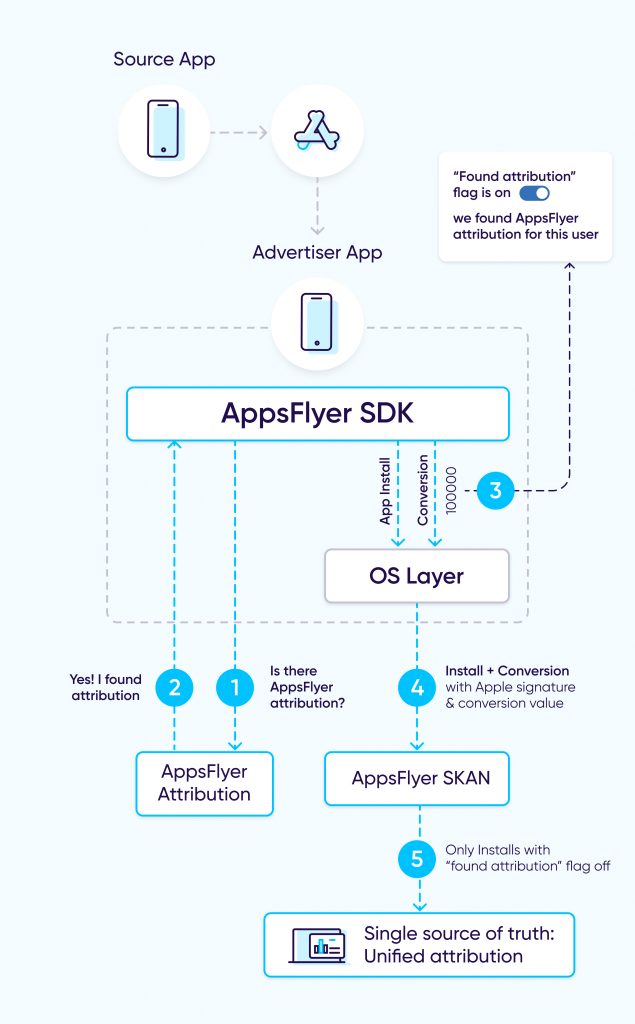
Critical milestones on the path to a single source of truth
In order for this to work, there is one important step in the process: advertisers must dedicate part of their conversion value to deduplication. This choice must be one that the advertiser can control and have the flexibility to turn on or off as they choose.
In the newly-released Conversion Studio, where advertisers can easily configure multi-metric conversion value mappings, we’re adding this very option.
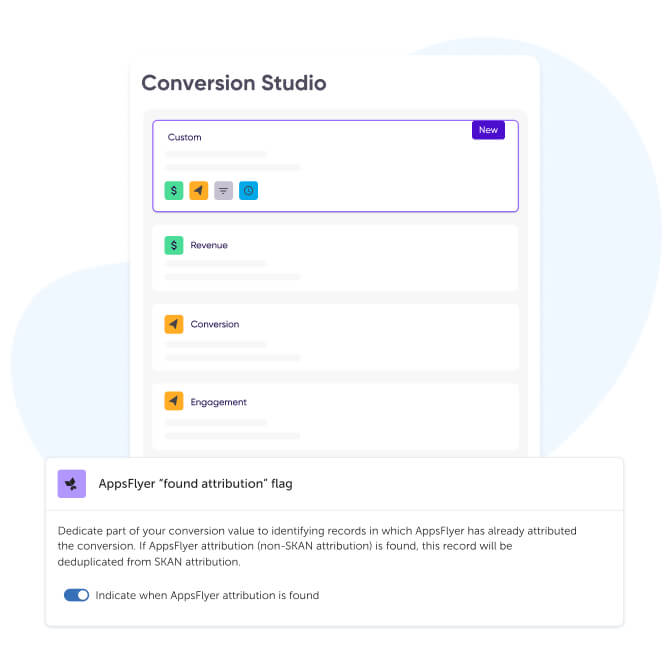
When toggled on, this setting will consolidate, deduplicate, and unify reported data in aggregate reports.
guide
Inside SKAN: SKAdNetwork insights
But wait, doesn’t it breach end user privacy?
Absolutely not. Data remains completely anonymized; thresholds, timers, and delays still ensure that no one can attain user-level granularity. All SKAdNetwork defense layers are still in place to ensure that end-user privacy is not harmed even a bit.
The bottom line remains fully aggregate with no means to de-anonymize the data. It just helps to deduplicate the aggregate realities and reach a purely aggregative single source of truth.
Let’s summarize real quick:
The pros
Siloed data points → Single source of Truth
The formula is simple:
Parallel realities → hard to make decisions
Single source of truth → actionable marketing insights
Maximize the advantages of each model
Once advertisers can deduplicate data from both aggregate models, they can enjoy benefits of each one, for example:
- Full LTV based on traditional attribution models
- Full coverage and deterministic data points from SKAdNetwork
Maximizing these advantages will help marketers make better decisions, even in an iOS 14+ reality.
No compromise on end users’ privacy
The SKAdNetwork privacy framework is in place and untouched.
SKAdNetwork campaign optimization remains the same
The fact that SKAdNetwork postbacks are sent for all users, whether they were also attributed in parallel modes or not, ensures that networks can continue optimizing based on SKAN conversion values.
The bottom line: the SKAN reality remains fully covered and accurate, hence everyone leveraging this data is not affected.
The cons
6 bits of conversion value → 5 bits of conversion value
As mentioned, one bit will be allocated to indicate whether or not the current install was also attributed in a parallel attribution mode. To allow this, the precious resource of conversion values will become a bit more limited (pun intended).
Some of our biggest customers took part as design partners in planning this solution, and they were more than willing to allocate a single bit for the promise of a single source of truth. Having said that, this is still a decision that needs to be made by the advertiser.
Final words
As the industry continues to acclimate to the new era, it is critical that data accuracy and user privacy continue to coexist. At AppsFlyer, it is our mission to empower advertisers as they go through these changes.
Having 100% certainty in the true results of your marketing efforts is mission-critical. A single source of truth for marketing performance ensures that marketers optimize their ad spend, grow their business, and supply superior experience to the end users.