


Introduction
Introduire un état d’esprit marketing plus rapide, et alimenté par les données
De nos jours, les consommateurs ont plus de choix que jamais. Ils peuvent facilement exploiter leurs capacités de scrolling pour obtenir à peu près tout ce qu’ils veulent, quand ils le veulent. Alimentée par la pandémie et une demande croissante de services digitaux et de divertissement, la concurrence sur le marché des applications est devenue plus féroce que jamais.
Garder une longueur d’avance est le seul moyen de rester compétitif. Et la modélisation prédictive permet justement cela, aidant les spécialistes marketing à comprendre les comportements et les tendances des consommateurs, à prévoir les actions futures et à planifier leurs campagnes en fonction de décisions fondées sur des données.
La science de l’analyse prédictive existe depuis des années et est utilisée par les plus grandes entreprises du monde pour perfectionner leurs opérations, anticiper les changements de l’offre et de la demande, prévoir les changements globaux et utiliser les données historiques pour mieux se préparer aux événements futurs.
Mais qu’est-ce que c’est que cette étrange invention de la science des données et du marketing, demandez-vous ?
La modélisation prédictive est une forme d’analyse qui tire parti du machine learning et de l’IA pour examiner les données de campagne historiques, les données de comportement des utilisateurs passés et des données transactionnelles supplémentaires pour prédire les actions futures.
Grâce à la modélisation prédictive, les spécialistes marketing peuvent prendre rapidement des décisions d’optimisation de campagne sans avoir à attendre les résultats réels. Par exemple, un algorithme de machine learning a constaté que les utilisateurs ayant terminé le niveau 10 d’un jeu dans les 24 premières heures étaient 80 % plus susceptibles d’effectuer un achat in-app dans l’application au cours de la première semaine.
Forts de ces connaissances, il est possible d’optimiser les contenus, une fois cet événement atteint dans les 24 heures, bien avant la fin de la première semaine. Si la campagne n’est pas performante, un investissement continu serait un gaspillage total de budget. Mais si c’est le cas, doubler rapidement les investissements peut générer des résultats encore meilleurs.
Qu’en est-il de la confidentialité ?
Quel impact la confidentialité a-t-elle sur la modélisation prédictive maintenant que l’accès aux données au niveau de l’utilisateur est limité ?
Les utilisateurs mobiles sont devenus de plus en plus fins et bien informés au cours des dernières années. Avec la confidentialité (ou l’absence de confidentialité) au centre de l’attention, l’utilisateur moyen n’est plus pressé de fournir ses données pour utiliser une application, ou même pour profiter d’une expérience plus personnalisée.
Mais, en 2021, les annonceurs sont-ils vraiment dans le flou quant à l’accès à des données de qualité ?
Pas nécessairement. En combinant la modélisation prédictive, SKAdNetwork, les données agrégées et l’analyse de cohorte, les spécialistes marketing peuvent prendre des décisions éclairées, même dans une réalité limitée par l’IDFA.
Mais par où commencer ? C’est une chose de mesurer les événements, de surveiller les performances et d’optimiser. C’est toute autre chose d’analyser une quantité massive de données, ainsi que de développer et d’appliquer des modèles prédictifs qui vous permettront de prendre des décisions agiles et précises basées sur des données.
Eh bien, n’ayez pas peur. Nous sommes là pour vous aider à donner un sens à tout cela.
Dans ce guide pratique – une collaboration entre AppsFlyer, l’agence de marketing digitalAppAgentet Incipia, nous allons explorer comment les spécialistes marketing peuvent élever leurs compétences en matière de données au niveau supérieur, et obtenir cet avantage concurrentiel convoité grâce à la modélisation prédictive.

Modélisation prédictive Concepts de base et configuration de mesure
Pourquoi construire des modèles prédictifs en premier lieu ?
La modélisation prédictive présente de nombreux avantages dans le marketing mobile, mais nous l’avons réduit à deux activités marketing clés :
1. Acquisition des utilisateurs (UA)
Connaître votre comportement d’utilisateur typique et les premiers jalons qui séparent les utilisateurs à fort potentiel des autres peuvent être utiles à la fois sur le front de l’acquisition et du réengagement .
Par exemple, si un utilisateur a besoin de générer X dollars au jour 3 pour réaliser un profit après le jour 30, et que ce chiffre est inférieur à votre benchmark, vous saurez que vous devrez ajuster les enchères, les créations, le ciblage ou d’autres choses dans afin d’améliorer le rapport coût/qualité de vos utilisateurs acquis, ou bien d’améliorer vos tendances de monétisation.
Si, toutefois, ce chiffre X dépasse votre benchmark, vous pouvez augmenter les budgets et les enchères pour tirer encore plus de valeur de vos utilisateurs acquis.
2. Publicité centrée sur la confidentialité
Pendant des années, le plus grand avantage de la publicité en ligne par rapport à la publicité traditionnelle a été la possibilité d’utiliser des larges quantités de données de performances mesurables, pour identifier le public cible souhaité.
Plus vos campagnes sont spécifiques, plus vous êtes susceptible d’augmenter la LTV des utilisateurs et d’optimiser la budgétisation. Mais que se passerait-il si vous pouviez ouvrir les portes à un échantillon plus large et avoir un aperçu immédiat de leur valeur potentielle ?
La modélisation prédictive vous permet de faire exactement cela ; élargir l’audience potentielle de votre campagne. En créant différents clusters de caractéristiques comportementales, votre audience peut alors être segmentée non pas par selon les identités, mais selon les interactions avec votre campagne à ses débuts.
Que dois-je mesurer ?
Pour comprendre ce que vous devez mesurer pour obtenir de bonnes prédictions, explorons quels data points sont utiles et ceux qui ne le sont pas :
Metrics
Toutes les métriques sont des data points, mais toutes les métriques ne sont pas des indicateurs de performance clés (KPI). Les métriques sont plus faciles à calculer et « mûrissent » beaucoup plus rapidement que les KPI, qui ont tendance à impliquer des formules complexes.
Notez qu’avec le SKAdNetwork d’Apple, les métriques suivantes peuvent toujours être mesurées, mais avec un niveau de précision moindre. Plus à ce sujet au chapitre 5.
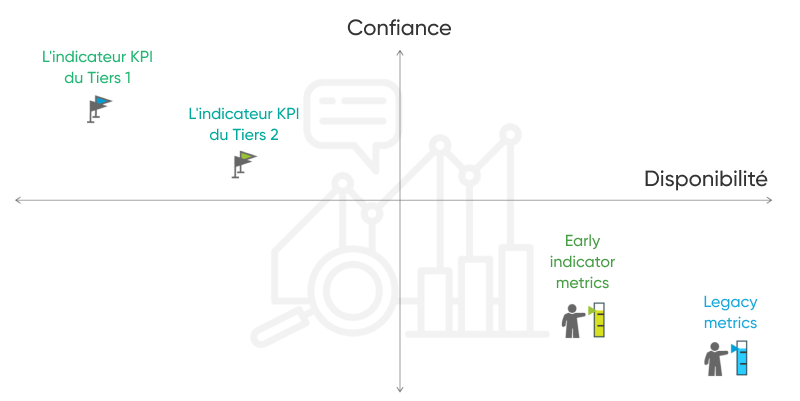
1) Les legacy metrics sont généralement identifiées avec une faible confiance dans la prévision des bénéfices, mais se caractérisent par une disponibilité la plus rapide :
- Le Click to install (CTI) En mesurant la conversion directe entre les deux points de contact (touchpoints) les plus forts sur un parcours utilisateur en pré-installation, le CTI est à la fois socialement et techniquement important, car des taux plus bas peuvent indiquer une audience non pertinente, des créatives inefficaces, ou un temps de chargement lent avant installation.
Formule: Nombre d’installations / Nombre de clics sur annonces
- Le Taux de clics (CTR) – le rapport entre un clic sur une annonce donnée et le nombre total de vues. Plus haut dans le funnel des ventes, le CTR a une valeur limitée pour informer d’autres objectifs marketing globaux, mais peut refléter directement l’efficacité de la création d’une campagne en fonction des clics reçus.
Calcul :Nombre de clics / Nombre de vues d’annonces
Les data points requis : impressions, clics, installations attribuées
2) Les « Early indicator metrics »sont généralement de confiance moyenne dans la prévision des bénéfices et de la disponibilité rapide.
À l’ère du funnel de vente inversé, l’installation n’est plus un KPI suffisant. Cela dit, les mesures suivantes, bien qu’elles ne soient pas utiles pour les prévisions de bénéfices, sont toujours utiles en tant qu’indicateurs précoces informant de la probabilité que leurs campagnes génèrent des bénéfices.
Les exemples incluent :
- Coût par installation (CPI) – En se concentrant sur les installations payantes plutôt que sur les installations organiques, le CPI mesure vos coûts UA en réponse à la visualisation d’une annonce.
Calcul : Dépenses publicitaires / total # d’installations directement liées à la campagne publicitaire
- Nombre d’utilisateurs de retour après une période donnée.
Calcul : [(CE – CN) / CS)] X 100
CE = nombre d’utilisateurs à la fin de la période
CN = nombre de nouveaux utilisateurs acquis au cours de la période
CS = nombre d’utilisateurs au début de la période
Data points requis : coût, installations attribuées, ouvertures d’application, (rapport de rétention)
À l’exception du taux de rétention, les mesures ont tendance à être liées à un modèle marketing plutôt qu’à votre modèle commercial et, en tant que telles, ne sont pas utiles pour déterminer si vos utilisateurs acquis généreront des bénéfices pour votre entreprise.
Si vous payez 100 $ par clic ou par installation, il y a de fortes chances que vous ne réalisiez aucun profit. Si votre CTR est de 0,05 %, il est probable que les mécanismes d’enchères vous obligeront à payer un taux élevé par installation, vous laissant encore avec moins de marge pour réaliser un profit.
Les métriques ne prennent pas en charge les prévisions lorsque vous essayez de calibrer votre plage de confiance avec une précision plus fine, par exemple – lorsque la fourchette de rentabilité se situe dans une espace compris entre 2 et 6 $.
Les KPIs
Il est important de diviser les KPI en deux catégories :
1) Les Tier 2 KPI confident predictors– définis par une confiance moyenne-élevée dans les prévisions de profit et une disponibilité lente :
Ceux-ci sont utiles pour servir de premiers repères de profit, offrant plus de confiance que les indicateurs avancés (metrics), les tier 2 KPIs prennent plus de temps à « mûrir » et offrent également moins de confiance que les Tier 1 KPIs.
* Notez qu’avec le SKAdNetwork d’Apple, les KPI suivants ne peuvent pas être mesurés ensemble.
- Coût d’acquisition client par utilisateur payant
- Coût ou conversion des actions clés – par exemple, ratio de jeux le premier jour joué ou ratio de vues de contenu lors de la première session
- Coût en fonction du temps ou conversion des actions clés (par exemple coût par nombre de parties jouées le premier jour ou coût par vue de contenu au cours de la première session)
- Coût par jour X pour utilisateur retenu: Dépenses totales par jour X du nombre d’utilisateurs retenus ce jour-là.
- Verticales spécifiques à des événements in-app – par exemple, achèvement du tutorial, achèvement du niveau 5 le jour 1 (jeu), nombre de pages de produits consultées lors de la 1ère session, nombre de sessions en 24 heures (shopping), etc.
Points de données requis : coût, installations attribuées, ouvertures d’application (rapport de rétention), événements in-app configurés et mesurés, données de session (time stamps, fonctionnalités utilisées, etc.)
Pour la plupart des modèles commerciaux, ces KPI ne peuvent pas servir de prédicteurs fiables car, bien qu’ils tiennent compte des coûts et des événements généralement corrélés au profit, ils manquent le côté monétisation de l’équation, étant donné que les ouvertures d’application ne sont pas toujours égales aux achats in-app, et les utilisateurs payants peuvent acheter plus d’une fois.
2) Le Tier 1 KPI confident predictors – revenus précoces et ROAS comme une indication de succès à long terme – ceux-ci sont marqués par une grande confiance dans la prévision des bénéfices, mais la disponibilité la plus lente :
Les Tier 1 KPI confident predictors mettent plus de temps à arriver à maturité ou impliquent des processus complexes à déterminer. Cependant, ils sont directement liés à votre modèle économique et, à ce titre, sont parfaitement adaptés pour prédire la rentabilité de vos campagnes marketing.
- Le ROAS correspond au budget consacré au marketing divisé par le revenu généré par les utilisateurs au cours d’une période donnée.
Lifetime Value (LTV) – Le montant des revenus que les utilisateurs ont générés pour votre application à ce jour.
Calcul : Valeur moyenne d’une conversion X Nombre # moyen de conversions au cours d’une période X Durée de vie moyenne du client
Points de données requis : coût, installations attribuées, ouvertures d’application, mesure approfondie des revenus (IAP, IAA, abonnement, etc.)
Bien que le ROAS soit plus facile à calculer, il faut des semaines, voire des mois, aux utilisateurs pour continuer à générer des courbes de revenus. Combiné avec le revenu moyen par utilisateur, la LTV est un excellent moyen pour déterminer le revenu potentiel total ou la valeur de vos utilisateurs.
Pour conclure, voici où se situe chaque approche dans le tableau suivant :

Avantages et inconvénients des différents modèles prédictifs basés sur la LTV : Points de vue des meilleurs spécialistes marketing
Construire un modèle LTV pour prédire le ROAS pourrait être hors de portée compte tenu de la complexité et des multiples concepts de prédiction existants.
Il existe des différences évidentes dans la manière dont les différents types d’applications retiennent et monétisent les utilisateurs ; pensez à quel point diffèrent les jeux d’achat in-app, les applications par abonnement et les entreprises de e-commerce.
Il est clair qu’un modèle LTV unique ne peut pas exister.
Pour mieux comprendre les complexités, nous avons parlé à un certain nombre d’experts de sociétés de jeux et non-gaming, notamment Hutch Games, Wargaming, Pixel Federationet Wolt, entre autres.
Voici les principales questions que nous avons couvertes :
- Quels modèles de LTV utilisez-vous ?
- Comment évolue votre modèle LTV dans le temps ?
- Qui dans l’entreprise est responsable de la gestion de la modélisation prédictive ?
- Quelle est votre métric phare en UA ?
- Quelle est votre position sur l’UA automation et les tendances futures ?
Modèles LTV
Sur la base de nos entretiens, il semble qu’il existe trois principales “écoles de pensée” pour les prédictions LTV :
1) Modèle de rétention axé sur la rétention / ARPDAU
- Concept: Modélisez une courbe de rétention basée sur quelques points de données de rétention initiaux, puis calculez le nombre moyen de jours actifs par utilisateur (pour le jour 90, D180, etc.) et multipliez-le par un revenu moyen par utilisateur actif quotidien (ARPDAU) pour obtenir la LTV prédite.
- Exemple : La rétention D1 / D3 / D7 est de 50% / 35% / 25%. Après avoir ajusté ces points de données à une courbe de puissance et calculé son intégrale jusqu’à D90, nous constatons que le nombre moyen de jours actifs est de 5. Sachant que l’ARPDAU est de 40 cents, la LTV D90 prédite serait égale à 2 USD.
- Ajustement adéquat : Applications à haute rétention (jeux tels que MMX Racing). Facile à configurer, peut être utile surtout s’il n’y a pas assez de données pour d’autres modèles.
- Mauvais ajustement : Les applications à faible rétention (par exemple, en eCommerce ) qui ne peuvent pas accéder à un nombre suffisant de points de données de rétention pour soutenir ce modèle.
2) Basé sur les ratios
- Concept: Calculez un coefficient (D90 LTV / D3 LTV) à partir des données d’historiques, puis pour chaque cohorte, et enfin – appliquez ce coefficient pour multiplier le D3 LTV réel pour obtenir une prédiction D90 LTV.
- Exemple : Après les 3 premiers jours, l’ARPU pour notre cohorte est de 20 cents. En utilisant des données d’historiques, nous savons que D90/D3 = 3. La LTV D90 prédite serait donc de 60 cents (20 cents ARPU*3).
- Dans le cas où il n’y a pas assez de données d’historiques pour calculer un ratio fiable (si par exemple nous n’avons que 50 jours de données et que nous voulons une prédiction LTV à D180, ou que nous avons trop peu d’échantillons de la LTV D180), une estimation initiale peut être faite en utilisant les points de données existants , puis affiné en continu au fur et à mesure que de nouvelles données arrivent.
Mais dans ces cas, il faut prendre ces estimations avec précaution.
- Ajustement adéquat: Types d’applications « standard » comprenant de nombreux genres de jeux ou applications de eCommerce .
- Mauvais ajustement: Applications par abonnement avec essai gratuit de plus d’une semaine. Beaucoup de temps peut s’écouler avant qu’un achat puisse avoir lieu, et comme cette méthode est basée sur l’achat, cela rendrait une prédiction impossible.
3) Prédictions basées sur le comportement
- Concept: Collecter un volume important de données auprès des utilisateurs consentants de l’application (données de session et d’engagement, achats, messagerie in-app, etc.) et les traiter à l’aide de régressions et de machine learning pour définir quelles actions ou combinaisons d’actions sont les meilleurs “prédicteurs” d’une nouvelle valeur de l’utilisateur.
Un algorithme attribue ensuite une valeur à chaque nouvel utilisateur en fonction d’une combinaison de caractéristiques (par exemple, plateforme ou canal UA) et d’actions effectuées (souvent au cours de quelques sessions ou jours initiaux).
Il est important de mentionner que depuis le lancement des contraintes de confidentialité d’Apple avec iOS 14, les prédictions au niveau de l’utilisateur ne sont plus possibles. Cela étant dit, les prédictions globales des utilisateurs le sont.
- Exemple : L’utilisateur A, c’est 7 longues sessions le jour 0 et au total – 28 sessions le jour 3. Ils ont également visité la page des prixs et y sont restés plus de 60 secondes.
La probabilité qu’ils fassent un achat dans le futur est de 65 %, selon l’analyse de régression et l’algorithme basé sur le machine learning. Avec un ARPPU de 100 USD, leur LTV prédite est donc de 65 USD.
- Ajustement adéquat: Pour toute application ayant accès à une équipe expérimentée en data science, à des ressources d’ingénierie et à de nombreuses données. Cela pourrait être l’une des très rares options viables dans certains cas (c’est-à-dire des applications d’abonnement avec un long essai gratuit).
- Limitations potentielles: Peut-être exagéré pour de nombreuses applications de petite et moyenne taille. Le plus souvent, des approches beaucoup plus simples peuvent produire des résultats similaires, sont beaucoup plus faciles à maintenir et à être comprises par le reste de l’équipe.
Choisir le bon modèle pour différents types d’applications
Chaque application et chaque équipe ont leur propre mélange de paramètres et de considérations qui doivent entrer dans le processus de sélection :
- Du côté du produit, il s’agit d’une combinaison unique de type et de catégorie d’application, de modèle de monétisation, de comportement d’achat des utilisateurs et de données disponibles (et leur variance).
- Du côté de l’équipe, il s’agit de la capacité, des compétences en ingénierie, des connaissances et du temps disponible avant que le modèle de travail ne soit requis par l’équipe UA.
Dans cette section, nous présenterons plusieurs exemples simplifiés du processus de sélection.
Celles-ci sont basées sur des cas réels de trois types d’applications : un jeu gratuit (F2P), une application par abonnement et une application eCommerce.

Applications par abonnement
Explorons deux cas d’applications basées sur un abonnement, chacune avec un type de paywall différent – une hard gate et un essai gratuit à durée limitée :
1. Le hard paywall: L’abonnement payant démarre très souvent au jour 0 (par exemple 8fit).
C’est parfait – cela signifie que nous aurons une indication très précise du nombre total d’abonnés déjà après le premier jour (par exemple, disons que 80 % de tous les abonnés le feront le J0, et les 20 % restants – dans le futur ).
À condition de connaître déjà nos taux de résiliation et par conséquent notre ARPPU, nous pourrions facilement prédire la LTV des cohortes en faisant simplement une multiplication de (nombre de payeurs)*(ARPPU pour un segment d’utilisateurs donné)*(1,25 comme coefficient représentant le 20 % supplémentaires estimés d’utilisateurs devraient payer à l’avenir).
2. Essai gratuit à durée limitée: Dans ce cas, un pourcentage d’utilisateurs se convertira pour devenir des abonnés payants après la fin de l’essai (par exemple, Headspace). Le problème est que les responsables UA doivent attendre la fin de l’essai pour comprendre l’évolution des taux de conversion.
Ce décalage peut être particulièrement problématique lors du test de nouveaux canaux et GEO, c’est pourquoi les prédictions comportementales pourraient être utiles ici.
Même avec un volume modéré de données et des régressions simples, il est souvent possible d’identifier des prédicteurs décents. Par exemple, nous pourrions apprendre que les utilisateurs qui entrent dans l’essai gratuit et ont au moins 3 sessions par jour pendant les 3 premiers jours après l’installation – se convertiront à l’abonnement dans 75 % des cas.
Bien qu’il soit loin d’être parfait, le prédicteur ci-dessus pourrait être suffisamment précis pour la prise de décision UA et fournir une bonne capacité d’action avant que davantage de données ne soient collectées et qu’un modèle approprié ne soit testé.
Les types et conceptions de paywall peuvent être fortement influencés par la nécessité d’évaluer rapidement le trafic.
Il est très utile de savoir si l’utilisateur convertira (ou non) le plus rapidement possible pour comprendre la rentabilité de la campagne et pouvoir réagir rapidement. Nous avons vu cela devenir l’un des facteurs décisifs pour plusieurs entreprises lors de la détermination d’un type de paywall.
Jeux Freemium
Les Free-to-play (F2P) (F2P) ont tendance à avoir un taux de rétention élevé et une quantité importante d’achats.
1) Jeu Casual (Diggy’s Adventure):
Le « modèle de ratio » est un bon choix pour les jeux basés sur l’achat in-app, où il devrait être possible de prédire en toute confiance la D(x)LTV après 3 jours, car nous devrions déjà avoir identifié la plupart de nos utilisateurs payants d’ici là.
Pour certains jeux monétisés via des publicités, l’approche basée sur la rétention pourrait également être envisagée.
2) Jeu hardcore (World of Tanks ou MMX Racing):
La distribution ARPPU des utilisateurs de jeux hardcore peut être considérablement faussée lorsque les utilisateurs les plus dépensiers – les “whales” – peuvent dépenser x fois plus que les autres.
Le « modèle de ratio » pourrait toujours fonctionner dans ces cas, mais devrait être amélioré pour prendre en compte différents niveaux de dépenses pour différents types de dépenses. Ici, une variable “type d’utilisateur” attribuerait différentes valeurs LTV aux utilisateurs en fonction de leur comportement de dépense (c’est-à-dire combien ils ont dépensé, combien d’achats, quel pack de démarrage ils ont acheté, etc.).
En fonction des données, une prédiction initiale pourrait être effectuée après le jour 3, et une autre un peu plus tard (jour 5 ou jour 7), une fois que l’on connaît les niveaux de dépenses des utilisateurs.
Les applications eCommerce
Les applications eCommerce ont généralement des modèles de rétention uniques, car leur lancement est souvent lié à une intention d’achat existante, ce qui n’arrive pas trop souvent d’ordinaire.
Nous pouvons donc conclure que l’utilisation du “modèle basé sur la rétention” n’est généralement pas adaptée à de telles applications. Au lieu de cela, explorons deux cas d’utilisation alternatifs :
1) Revendeur de billets d’avion
Le délai entre l’installation et l’achat est important dans le secteur du voyage, parfois long de plusieurs mois. Étant donné que les achats et les revenus sont répartis sur une longue période, les modèles de « ratio » ou de « rétention » ne fonctionneront pas dans la plupart des cas.
Par conséquent, nous devrions chercher à trouver des indices comportementaux et à découvrir des prédicteurs potentiels lors de la première session post-installation, car c’est souvent la seule information que nous aurons à notre disposition.
En utilisant ces indices, et étant donné qu’il y a suffisamment de données, nous estimerions la probabilité qu’un utilisateur achète un billet, et la multiplierions par un ARPPU pour une combinaison pertinente de leurs caractéristiques (plateforme, pays d’origine, etc.)
2) Marketplace en ligne
Les utilisateurs ont tendance à effectuer leur premier achat peu de temps après une installation. Et le premier article acheté prend souvent un temps considérable à être expédié. Par conséquent, les clients ont tendance à attendre le premier envoi pour évaluer le service avant de s’engager dans un autre achat.
Attendre le lot de données lié au « deuxième achat » rendrait les prévisions inutilisables en raison du long délai, et limiterait par la suite tous les calculs aux données initiales.
Selon le moment où les utilisateurs passent leurs commandes (la majorité le faisant dans les 5 premiers jours), nous pouvons utiliser la méthode du ratio (D90/D5) et multiplier le résultat par un autre coefficient qui tiendrait compte des achats futurs.
Du MVP aux modèles complexes
Tous les analystes de données avec lesquels nous avons parlé chez les grands éditeurs ont convenu qu’il est important de commencer vos prédictions avec un simple « Produit minimum viable » (MVP).
L’idée est de vérifier les hypothèses initiales, d’en savoir plus sur les données et de construire progressivement un modèle. Cela signifie généralement ajouter plus de variables au fur et à mesure pour activer des modèles plus granulaires et précis (par exemple , le facteur k, la saisonnalité et les revenus publicitaires, en plus de la segmentation initiale par plate-forme, pays et canal UA).
Complexe n’est pas synonyme de “bon”. Les responsables UA peuvent être rapidement frustrés lorsque leur accès aux données est bloqué parce que quelqu’un fait des choses compliquées. »
Anna Yukhtenko, Data Analyst @Hutch Games
En réalité, nous avons constaté que les entreprises ont tendance à s’en tenir à des modèles conceptuellement simples.
C’était un peu une découverte surprenante. Nous nous attendions à ce que, une fois le produit lancé, les équipes de données sortent leurs artifices, leurs algorithmes de machine learning et leurs IA pour se mettre au niveau de ce que nous pensions être une norme de l’industrie. Nous avions tort. Ou du moins partiellement.
Bien que beaucoup voient la valeur des modèles sophistiqués et les aient testés dans le passé, la plupart ont finalement opté pour des modèles plus simples. Trois raisons principales à cela.
1. Coût/bénéfice des modèles avancés
Le rapport coût/bénéfice de la création et de la maintenance d’un modèle complexe ne correspond tout simplement pas. Si un niveau de confiance suffisant pour les opérations quotidiennes peut être atteint avec des modèles plus simples, pourquoi s’en soucier ?
2. Temps d’ingénierie pour créer/maintenir
La création d’un modèle avancé peut engloutir de nombreuses heures d’ingénierie, et encore plus pour le gérer, ce qui est un énorme problème pour les petites équipes.
Très souvent, le département BI a très peu de capacité à consacrer à l’équipe marketing, laissant les marketeurs mener seuls une bataille inégale contre les statistiques et l’ingénierie des données.
3. Changements continus
Chaque version de produit est différente et est monétisée différemment (l’ajout ou la suppression de fonctionnalités peut avoir un effet considérable, par exemple) ; la saisonnalité locale et les effets à l’échelle du marché en sont deux exemples pertinents.
Les modifications doivent être apportées à la volée, et l’introduction de modifications dans un modèle complexe peut être un processus douloureux et lent, qui peut s’avérer désastreux dans un environnement mobile en évolution rapide avec des achats de médias continus.
Il est tellement plus facile de modifier un modèle simple, parfois par les spécialistes marketing eux-mêmes.
Pour un certain sous-ensemble d’applications, un modèle basé sur le comportement peut être le seul bon choix. Et tandis qu’une équipe expérimentée d’ingénierie et de data science devrait être à portée de main pour les entreprises suffisamment grandes pour soutenir un tel investissement, d’autres peuvent opter pour l’adoption d’un produit prêt à l’emploi qui offre des qualités similaires.
Un autre ensemble de données qui gagne du terrain est celui des modèles LTV générés par la publicité avec des estimations de revenus publicitaires au niveau de l’utilisateur. Pour plus d’informations à ce sujet, voir le chapitre 4.
Equipes et responsabilités
En général, la conception, la mise en place et l’adaptation d’un modèle LTV prédictif devraient être le travail d’une équipe d’analyse/data science (à condition qu’il y en ait une).
Idéalement, il y a deux rôles en jeu ici : un analyste expérimenté avec une large portée en marketing, apte à donner des conseils sur la stratégie et les niveaux tactiques, ainsi que décider quel modèle doit être utilisé, et comment. Et un analyste dédié qui “possède” les calculs et les prévisions LTV au jour le jour.
L'”analyste au jour le jour” doit surveiller en permanence le modèle et garder un œil sur toute fluctuation significative. Par exemple, si les revenus hebdomadaires prévus ne correspondent pas à la réalité et ne se situent pas dans les limites prédéfinies, une modification du modèle peut être nécessaire immédiatement, et non après quelques semaines ou mois.
« C’est un travail d’équipe. Nous avons créé quelque chose comme un système d’alerte précoce où nous nous réunissons une fois par mois, passons en revue toutes les hypothèses qui entrent dans le modèle et vérifions si elles sont toujours vraies. Jusqu’à présent, nous avons environ 12 hypothèses majeures (par exemple, la valeur des incremental organics, la saisonnalité, etc.), que nous contrôlons pour nous assurer que nous sommes sur la bonne voie. »
Tim Mannveille, directeur du Growth & Insight @Hutch Games
Une fois les résultats de prédiction calculés, ils sont automatiquement transmis et utilisés par l’équipe UA. Les UA managers se fient le plus souvent simplement à ces résultats et signalent les incohérences, mais ils devraient essayer de monter d’un cran afin de mieux remettre en question et évaluer les modèles utilisés à un niveau général (comprendre les subtilités derrière un modèle complexe et ses calculs est non requis).
Professionnels du marketing interrogés pour ce chapitre :
- Fredrik Lucander de Wolt
- Andreï Evsa de Wargaming
- Matej Lancaric de Boombit (anciennement chez Pixel Federation)
- Anna Yukhtenko et Tim Mannveille de Hutch Games

Méthodes d’évaluation de la rentabilité du marketing mobile avec Excel
Si vous pensez maîtriser un Excel avancé en utilisant des tableaux croisés dynamiques, des champs calculés, une mise en forme conditionnelle et des recherches, vous pourriez être surpris d’apprendre que vous manquez une astuce encore plus puissante dans le playbook Excel.
Non seulement cela, mais cette astuce peut être utilisée pour prédire la rentabilité de vos campagnes de marketing mobile !
Considérez le chapitre suivant comme votre mini-guide pour créer votre propre modélisation prédictive à l’aide d’outils de tous les jours.
Avertissement : Gardez à l’esprit que ce qui suit est une variante très simplifiée d’un modèle prédictif. Pour les exploiter correctement à grande échelle, des algorithmes sophistiqués de machine learning sont nécessaires afin de prendre en compte de nombreux éléments susceptibles d’affecter considérablement les résultats. L’examen d’un seul facteur pour prédire sa valeur (c’est-à-dire les revenus) entraînera probablement un manque de précision.
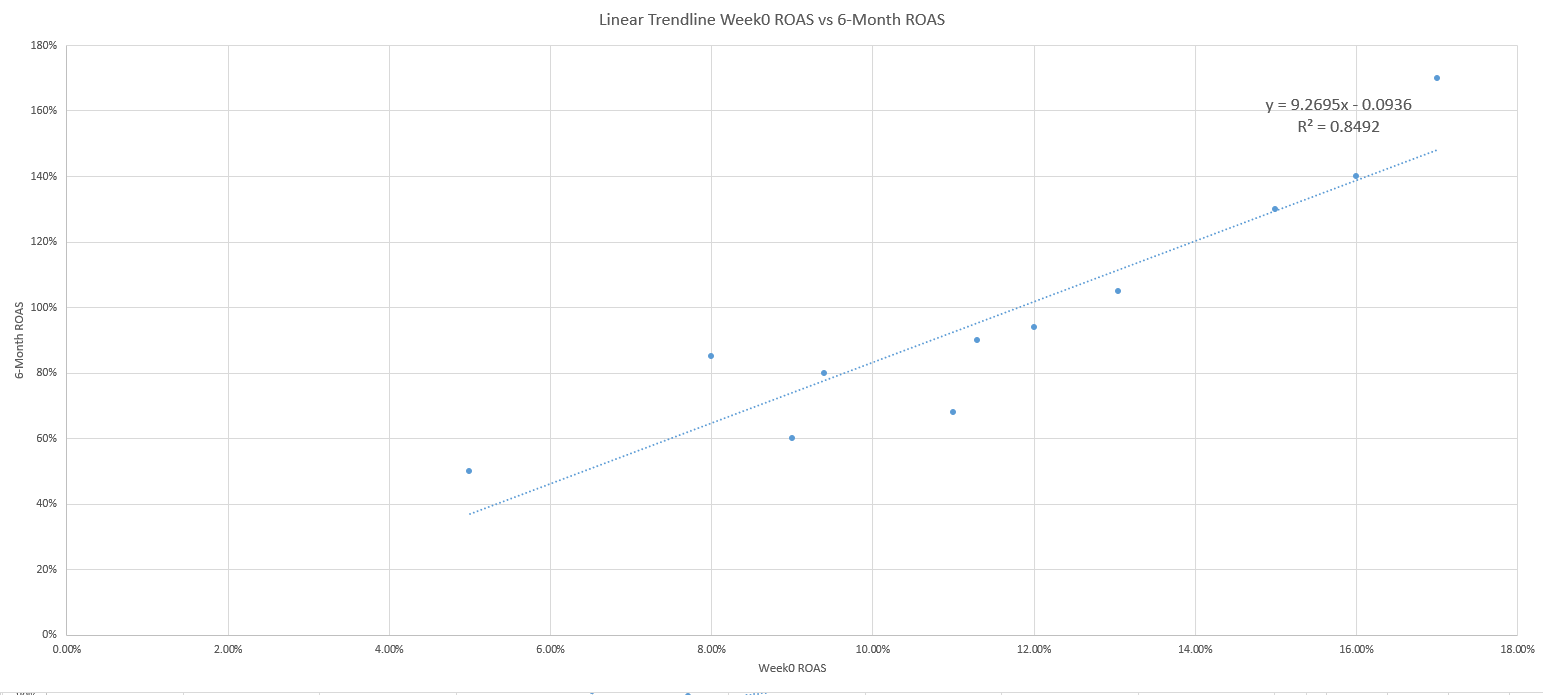
En utilisant un nuage de points et un peu d’algèbre, vous pouvez transformer une équation de courbe de tendance Excel en un outil puissant, comme l’identification précoce du point auquel vos campagnes marketing prouvent qu’elles sont susceptibles de générer des bénéfices.
Cette méthode peut vous aider à passer d’intuitions à la prise de décision basée sur les données et à augmenter votre confiance dans les rapports hebdomadaires.
Prédire quel ROAS à la semaine 0 prédira un ROAS de 100 % à 6 mois
Alors que la LTV bien faite est un excellent prédicteur, le ROAS – en particulier au cours de la première semaine de la vie d’un utilisateur – est une mesure largement utilisée pour mesurer les bénéfices en raison de sa large accessibilité.
En particulier, nous allons utiliser le ROAS de la semaine 0 (revenus de la première semaine d’acquisition d’utilisateurs/coût d’acquisition de ces utilisateurs) comme prédicteur de confiance, qui est une méthode par cohorte entre semblables, pour comparer les performances des annonces chaque semaine.
Le ROAS de la semaine 0 nous permettra de prédire si nous atteindrons le seuil de rentabilité de nos dépenses publicitaires avec un ROAS de 100 % après 6 mois.
Étape 1
La première étape pour utiliser Excel et prédire les bénéfices consiste à vous assurer que vous disposez de suffisamment de points de données pour les semaines 0 et 6 mois. Bien que vous puissiez techniquement dessiner une pente et faire une prédiction pour n’importe quel point sur cette pente, avec deux points de données, votre prédiction sera loin d’être solide avec si peu d’observations l’alimentant.
Le nombre idéal d’observations dépend d’une multitude de facteurs ; tels que votre niveau de confiance souhaité, les corrélations dans l’ensemble de données et les contraintes de temps, mais en règle générale pour les prévisions basées sur le ROAS de la semaine 0, vous devez viser au moins 60 paires d’observations ROAS de la semaine 0 et de 6 mois.
Il est également essentiel d’inclure suffisamment d’observations qui ont atteint le niveau d’objectif que vous avez défini. Si vous avez 60 points de données à tracer, mais seulement 2 points où le ROAS sur 6 mois a dépassé 100 %, votre modèle d’équation ne sera pas alimenté par une compréhension suffisante des entrées nécessaires pour atteindre ce seuil de rentabilité.
Dans ce cas, l’exigence d’atteindre un ROAS de 100 % après 6 mois pourrait être soit 2 points de pourcentage de ROAS complets supplémentaires, soit 5 points de pourcentage, ce qui représente une plage très large qui n’est pas propice à la prédiction.
Étape 2
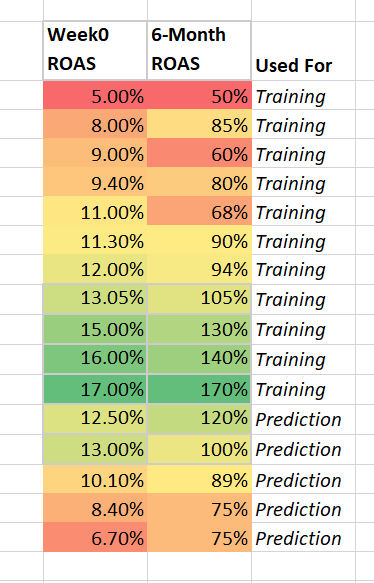
Une fois que vous avez recueilli suffisamment d’observations sur le niveau d’objectif, la deuxième étape consiste à diviser votre ensemble de données en deux groupes, un pour l’entraînement et un pour la prédiction.
Placez l’essentiel des données (~ 80 %) dans un training group. Plus tard, vous utiliserez le groupe de prédiction pour tester la précision de votre modèle et prédire le ROAS sur 6 mois, compte tenu du ROAS de la semaine 0.
Étape 3
La troisième étape consiste à utiliser un nuage de points pour représenter graphiquement les données, avec le ROAS de la semaine 0 sur l’axe des x et le ROAS sur 6 mois sur l’axe des y.
Ajoutez ensuite une ligne de tendance et ajoutez les R-squared settings.
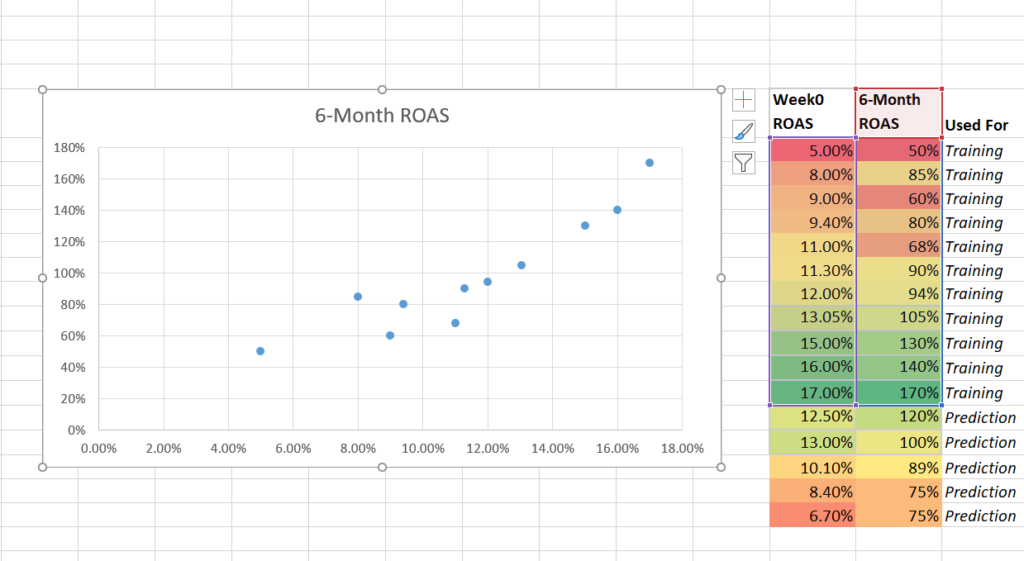
Représentez graphiquement les données d’apprentissage à l’aide d’un nuage de points.
Faites un clic droit sur un point de données et ajoutez une ligne de tendance.
Ajoutez l’équation de la ligne de tendance et le R-squared.
Étape 4
La quatrième étape consiste à utiliser l’équation linéaire y = mx + b pour résoudre la valeur x de l’équation (ROAS de la semaine 0) lorsque la valeur y (ROAS sur 6 mois) est de 100 %.
Le réarrangement de l’équation à l’aide de math se fait comme suit :
1. y = 9,2695x – 0,0936
2. 1 = 9.2695x – .0936
3. 1 + .0936 = 9.2695x
4. 1.0936 = 9.269x
5. X
6. X = 11.8%
De cette façon, comment prédire le profit à 6 mois ? Votre ROAS doit être supérieur à 11,8 % la première semaine.
Si votre ROAS de la semaine 0 est inférieur à ce taux, vous savez que vous devrez ajuster les enchères, les créatives ou le ciblage pour améliorer le coût/la qualité de vos utilisateurs acquis et améliorer vos tendances de monétisation.
Si votre ROAS de la semaine 0 est supérieur à ce chiffre, vous pouvez augmenter vos budgets et vos enchères en toute confiance !
Étape 5
La cinquième étape consiste à utiliser votre segment de prédiction de l’ensemble complet de données pour évaluer dans quelle mesure votre modèle a pu prédire les résultats réels. Cela peut être évalué à l’aide de l’erreur absolue moyenne en pourcentage (MAPE), qui est un calcul divisant la valeur absolue de l’erreur (la valeur réelle moins la valeur prédite) par la valeur réelle.
Plus la somme du MAPE est faible, meilleure est la puissance prédictive de votre modèle.

Il n’y a pas de règle empirique pour un bon nombre MAPE, mais généralement, plus votre modèle contient de données et plus les données sont corrélées, meilleure sera la puissance de prédiction de votre modèle.
Si votre MAPE est élevé et que les taux d’erreur sont inacceptables, il peut être nécessaire d’utiliser un modèle plus complexe. Bien que plus difficiles à gérer, les modèles impliquant R et python) peuvent augmenter la puissance de prédiction de votre analyse.
Voilà donc : votre cadre pour prédire la rentabilité des campagnes marketing.
Mais ne partez pas tout de suite ! Ce guide contient quelques autres conseils de choix…
Améliorez vos pronostics
Les lecteurs curieux se demanderont si la ligne de tendance linéaire par défaut est la meilleure à utiliser pour prédire les bénéfices.
Vous pouvez même essayer quelques lignes de tendance supplémentaires et découvrir que le R-squared (une mesure de l’ajustement de l’équation à vos données) s’améliore avec d’autres équations, ce qui rehausse encore plus le profil de cette question.
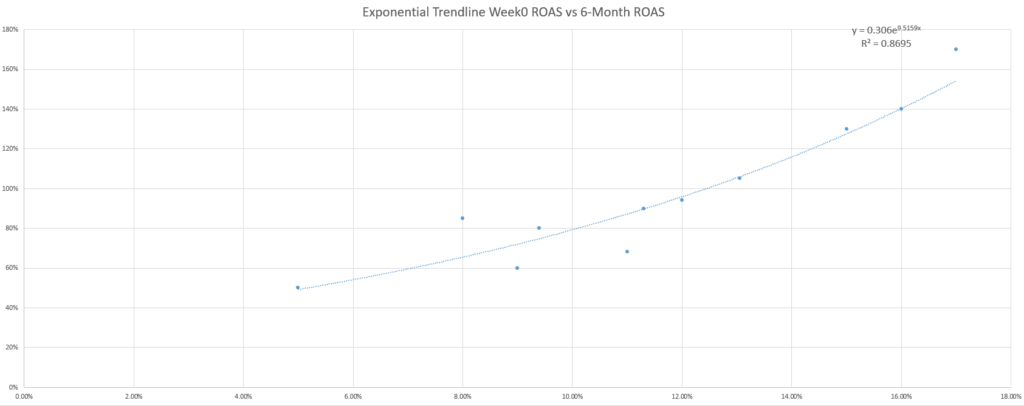
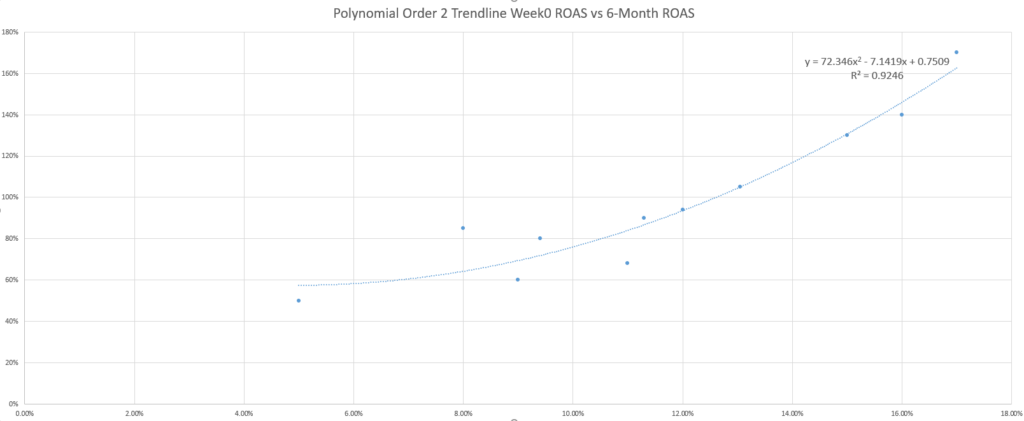
Alors que l’adage marketing du “ça dépend” s’applique à nouveau dans la sélection de la meilleure ligne de tendance, un autre adage marketing anglo-saxon se montre utile : Le KISS (keep it simple, stupid). Si vous n’êtes pas un statisticien ou un passionné de mathématiques, votre meilleur pari est d’utiliser les courbes de tendance les plus simples – qui sont les courbes linéaires.
Pourquoi est-ce un enjeu ? À titre d’exemple simple, considérons l’ajout de données inattendues dans le modèle. Dans les deux scénarios suivants, voyez comment un ROAS inférieur de la semaine 0 arrivant à maturité de manière inattendue ou un ROAS supérieur de la semaine 0 arrivant à maturité de manière inattendue affecte la précision de chaque modèle de courbe de tendance (évaluée à l’aide du MAPE).

L’utilisation du MAPE pour comparer les différents modèles basés sur les courbes de tendance montre ici que, bien que les modèles linéaires et exponentiels ne soient pas les plus précis dans tous les cas, ils sont les plus cohérents.
De plus, du machine learning peut vous donner la possibilité d’automatiser ce processus, d’analyser de plus grandes quantités de données et de fournir des informations plus rapidement.
S’assurer que vous allez dans le bon sens
Pour finir, consultez cette liste de questions supplémentaires qui peuvent s’avérer utiles pour vous assurer que votre analyse de prédiction repose sur des bases solides :
- Avez-vous continué à alimenter votre modèle pour le maintenir formé sur les données les plus pertinentes ?
- Avez-vous vérifié si les prédictions de votre modèle se concrétisent sur la base de nouvelles observations ou s’en rapprochent ?
- Avez-vous trop ou pas assez de variations ?
- Un R-squared très faible ou bien très élevé indiquent un problème dans la capacité de votre modèle à prédire avec précision de nouvelles données.
- Avez-vous utilisé le bon KPI ?
- Poursuivez et testez différents KPI (par exemple, plus ou moins de jours de ROAS ou de LTV) et utilisez le MAPE pour comparer le pouvoir de prédiction des bénéfices de chacun.
Vous serez peut-être surpris de voir à quel point les mesures standard sont peu corrélées.
- Vos indicateurs avancés ou vos premiers benchmarks ont-ils connu des changements significatifs ?
- Cela peut être un signe que quelque chose d’important a changé dans le monde réel et que des problèmes se préparent pour la capacité de votre modèle à prédire avec précision les bénéfices à l’avenir.
- Avez-vous appliqué une segmentation aux données ?
- La segmentation des utilisateurs en groupes plus homogènes est un excellent moyen de réduire le « bruit » et d’améliorer la puissance prédictive de votre modèle.
Par exemple, n’appliquez pas le même modèle à tous les utilisateurs sur tous les canaux et toutes les zones géographiques si ces utilisateurs ont des tendances de rétention et de coût très différentes.
- Considérez-vous les influences du temps?
- La plupart des spécialistes marketing sont conscients que la saisonnalité est un facteur pour lequel les prédictions peuvent échouer, mais le cycle de vie de votre application/campagne/audience/création peut également influencer la capacité de votre modèle à faire des prédictions précises.

Ajout d’une autre pièce au puzzle : Prédire la LTV des annonces in-app
La publicité in-app (IAA) est devenue de plus en plus populaire, représentant au moins 30 % des revenus des applications ces dernières années. Les jeux hyper-casual et casual, en plus de nombreuses applications utilitaires, exploitent naturellement ce flux de revenus comme principale source de monétisation.
Même les développeurs qui dépendaient entièrement des achats in-app (IAP) ont commencé à monétiser leur activités avec des publicités. En conséquence, nous pouvons voir que de nombreuses applications combinent désormais avec succès les deux sources de revenus pour maximiser la LTV de leurs utilisateurs.
A titre d’exemple, ne cherchez pas plus loin que King’s Candy Crush.
La LTV de la monétisation hybride est composée de deux parties :
- Achats in-app/Abonnement LTV : Revenu activement généré par un utilisateur qui fait des achats in-game, des monnaies in-app, des contenus spéciaux, des services supplémentaires ou un abonnement payant.
- Publicité LTV in-app Revenus générés passivement par un utilisateur qui visualise et/ou interagit avec des publicités (bannières, vidéos, interstitiels, etc.)
Le défi des données
Idéalement, les spécialistes marketing devraient être en mesure de comprendre la valeur nominale de chaque impression ; cela en ferait pratiquement un « achat ». Après avoir collecté suffisamment de données, nous serons en mesure de créer des modèles de prédiction similaires à ce que nous avons déjà décrit au chapitre 2 pour les achats in-app.
Mais dans le monde réel, ce n’est pas si simple – même le calcul de la LTV des annonces in-app est difficile en raison du volume et de la structure des données sur les revenus, visibles des marketeurs.
Voici une liste de quelques problèmes récurrents :
- Il y a rarement une seule source d’annonces qui est affichée. En pratique pourtant, il existe de très nombreuses sources, avec un algorithme/outil derrière elles (plateformesde médiation publicitaire ) qui changent constamment de sources et d’eCPM.
- Si un utilisateur visualise 10 annonces, il est tout à fait possible qu’elles proviennent de 5 sources différentes, chacune avec un eCPM complètement différent lui aussi.
- Certains réseaux publicitaires paient pour les actions (installation, clic) plutôt que pour les impressions, ce qui complique encore plus les choses.
- Lorsque vous travaillez avec des plateformes de médiation couramment utilisées offrant des revenus publicitaires au niveau de l’utilisateur, le nombre obtenu reste une estimation. Les réseaux publicitaires sous-jacents ne partagent pas ces données la plupart du temps, ce qui entraîne généralement une répartition entre les revenus générés avec les utilisateurs qui ont vus les impressions.
- Les eCPM peuvent varier considérablement au fil du temps et il est impossible de prévoir ces changements.
Modèles de prédiction pour la LTV des annonces in-app
De nombreuses entreprises que nous avons interrogées n’étaient pas activement impliquées dans les prévisions de LTV publicitaires. Parmi les marketeurs des app de jeu qui s’intéressaient au sujet, aucun n’avait réellement compris la valeur ajoutée de son utilisation. En tout cas, pas à court terme.
Voici les concepts qui ont été discutés comme points de transition :
1. Le modèle de rétention basé sur la rétention/ARPDAU
- Concept: Utilisation du modèle de rétention ARPDAU, qui dans ce cas contient également la contribution supplémentaire des revenus publicitaires in-app.
- Exemple : La rétention D1/D3/D7 est de 50 %/35 %/25 %. Après avoir ajusté ces points de données à une courbe de puissance et calculé son intégrale jusqu’à D90, nous apprenons que le nombre moyen de jours actifs est de 5. Sachant que l’ARPDAU est de 50 centimes, le LTV D90 prévu serait donc de 2,50 $.
2. La méthode basée sur les ratios
- Concept: Intégrer les estimations de revenus publicitaires au niveau de l’utilisateur dans le stack afin d’utiliser la méthode du ratio de la même manière (c’est-à-dire sur la base des coefficients de D1, D3, D7, etc.).
- Exemple : L’ARPU calculé à partir des achats in-app et des revenus publicitaires intégrés à l’application est de 40 cents après les 3 premiers jours. On sait que D90/D7 = 3. Le LTV D90 prévu serait donc de 1,20 $.
3. La simple méthode de multiplication
- Concept: Calcul du ratio entre les achats in-app et les revenus publicitaires, pour utiliser un multiplicateur dans le calcul de la LTV totale. Avec plus de données, plusieurs coefficients peuvent être calculés pour les dimensions plateforme/pays, car ceux-ci ont généralement le plus grand impact sur le ratio des revenus publicitaires par rapport aux revenus in-app.
Lien vers les prédictions LTV basées sur le comportement
Il est important de mentionner un autre facteur clé qui peut fortement influencer la rentabilité potentielle des utilisateurs de l’application : la cannibalisation.
Les utilisateurs qui dépensent de l’argent en effectuant des achats in-app ont souvent une LTV nettement plus élevée que les utilisateurs qui ne font que consommer des publicités. Il est de la plus haute importance que leur « intention » première ne soit pas perturbée par des messages pratiques et gratuits.
D’un autre côté, il est important d’inciter les utilisateurs à regarder des publicités, afin qu’ils soient souvent récompensés par de la monnaie in-app ou des bonus.
Si une application contient à la fois des publicités avec récompense et des achats in-app, il est possible qu’à un certain moment, un joueur ne reçoive pas de récompense importante en monnaie in-app, en échange du visionnage de publicités, il pourrait devenir un consommateur IAP.
C’est exactement là que les prédictions comportementales entrent en jeu – en mesurant le comportement des utilisateurs, un algorithme de machine learning peut déterminer la probabilité que certains utilisateurs deviennent des “dépensiers” et indiquer où certains ajustements del’expérience de jeu/application sont nécessaires.
Le processus fonctionne comme suit :
- Tous les utilisateurs doivent commencer par une expérience sans publicité pendant que les données d’engagement commencent à être mesurées.
- L’algorithme calcule en continu une probabilité qu’un utilisateur devienne un « spender ».
- Si cette probabilité est supérieure à un pourcentage défini, les annonces ne seront plus diffusées au fur et à mesure que des données supplémentaires seront collectées (“en attente de l’achat”).
- Si la probabilité tombe en dessous d’un pourcentage défini, il est fort probable que cet utilisateur n’effectuera jamais d’achat. Dans ce cas, l’application commence à diffuser des annonces.
- Basé sur le comportement à plus long terme des joueurs, l’algorithme peut continuer à évaluer leur comportement tout en modifiant le nombre d’annonces et en mélangeant différents formats.
La plupart des entreprises se contenteront d’utiliser des modèles et des approches simples qui offriront le rapport coût/bénéfice optimal, en particulier en ce qui concerne les difficultés de mise en œuvre et la valeur ajoutée d’informations plus précises.
Des progrès rapides dans ce domaine sont déjà visibles, avec différentes solutions qui viennent combler les lacunes et compléter le rythme de développement effréné de l’écosystème, ainsi que l’importance croissante de la publicité in-app en tant que source de revenus clé pour les applications.
Le mode de contribution
Alors que des méthodes de prédiction de comportement bien réglées peuvent donner les résultats les plus précis dans l’attribution des revenus publicitaires, il existe une méthode plus simple et plus viable pour gérer le problème de l’attribution des revenus publicitaires à une source d’acquisition.
Cette méthode est basée sur l’attribution de la contribution d’un canal aux revenus publicitaires en fonction de points de données agrégés sur le comportement des utilisateurs.
Les marges de contribution fonctionnent à partir de la contribution d’un canal par rapport au comportement global de l’utilisateur, qui est ensuite convertie en marge de gain de ce même canal, par rapport aux revenus publicitaires globaux générés par tous les utilisateurs.
La théorie est que plus les utilisateurs acquis par un canal génèrent des actions dans une application, plus ce canal est influent et peut réclamer le crédit des revenus publicitaires de ces utilisateurs.
Pour clarifier, décomposons-le calcul :
Étape 1
La première étape consiste à sélectionner un point de données à utiliser pour déterminer la marge de contribution aux revenus publicitaires de chaque source d’acquisition.
Comme point de départ, vous pouvez utiliser la régression de la courbe de tendance d’Excel pour identifier quel KPI du comportement des utilisateurs se trouve être le plus corrélé avec les changements de revenus publicitaires.
Notez que, étant donné que la méthode de contribution implique l’attribution de revenus en fonction d’une proportion de l’activité totale, vous souhaiterez utiliser un point de données qui correspond à un nombre d’ utilisateurs actifs par jour, plutôt qu’à un taux de rétention de type ratio.
Quelques options incluent :
- Nombre total d’utilisateurs actifs
- Nombre total de sessions utilisateur
- Durée totale de la session
- Données attribuables aux annonces (par exemple, impressions d’annonces)
- Nombre total d’événements clés (par exemple, les jeux joués)
Étape 2
Une fois que vous avez quelques points de données à observer, répartissez chaque point de données par rapport aux revenus publicitaires totaux par jour afin de voir où les corrélations entre les changements de comportement des utilisateurs et les revenus publicitaires totaux sont les plus fortes.
Étape 3
Ajoutez le point de données R-squared à votre graphique pour identifier quel point de données obtient la corrélation la plus forte.
Il y a un inconvénient à cette méthode de régression de la ligne de tendance Excel : moins il y a de variation dans le comportement des utilisateurs et des revenus publicitaires, plus le modèle perd en capacité de précision pour observer la force de la corrélation entre les points de données.
Par conséquent, vous aurez moins confiance en votre capacité à choisir un point de données plutôt qu’un autre.
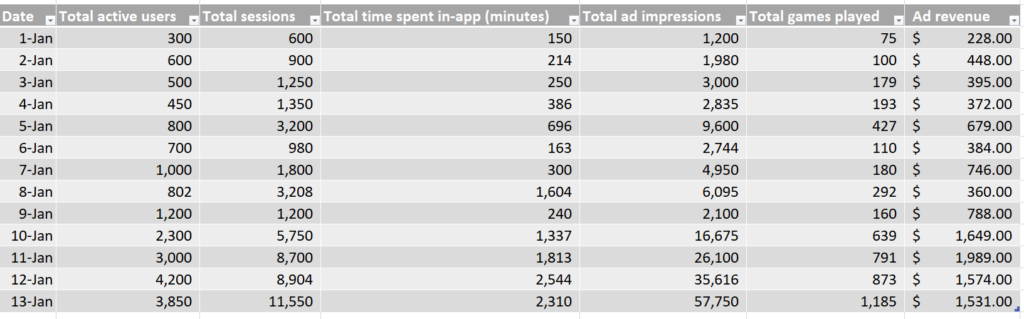
Dans cet ensemble de données simulées, nous observons le nombre de chaque point de données, par jour, ainsi que le total des revenus publicitaires générés par jour.
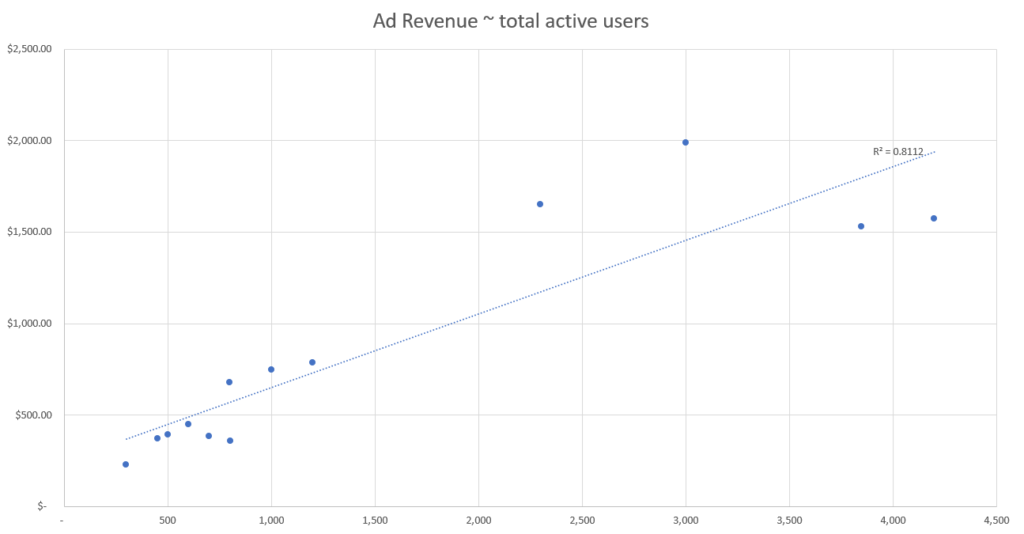
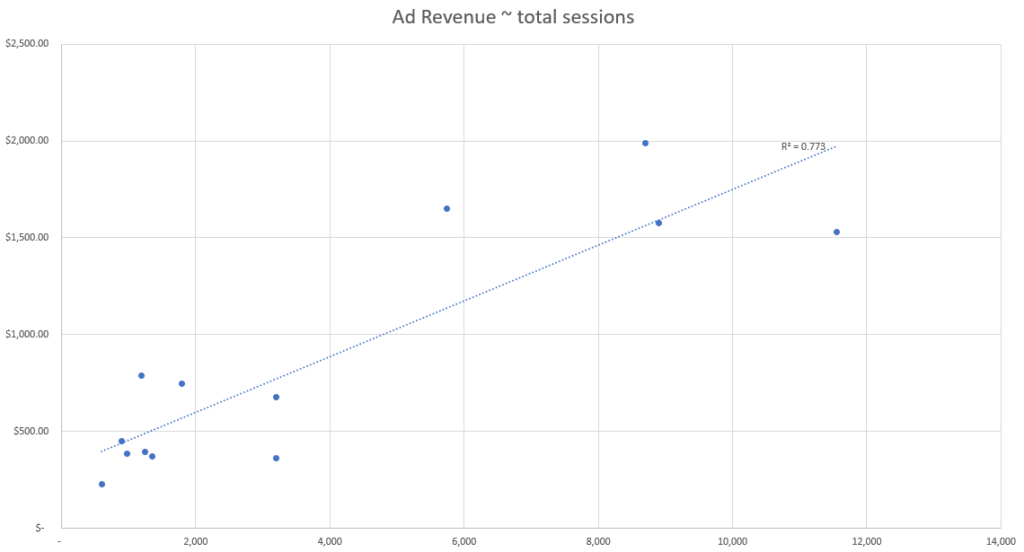
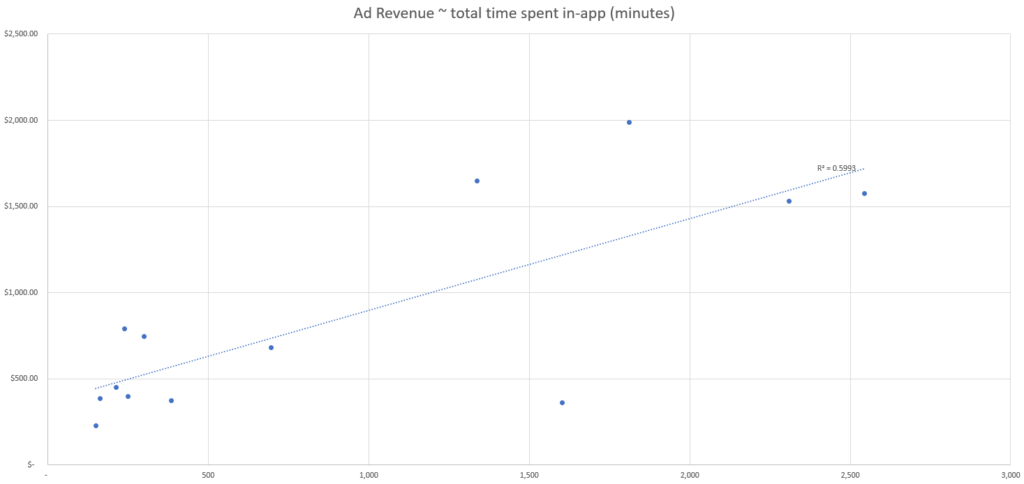
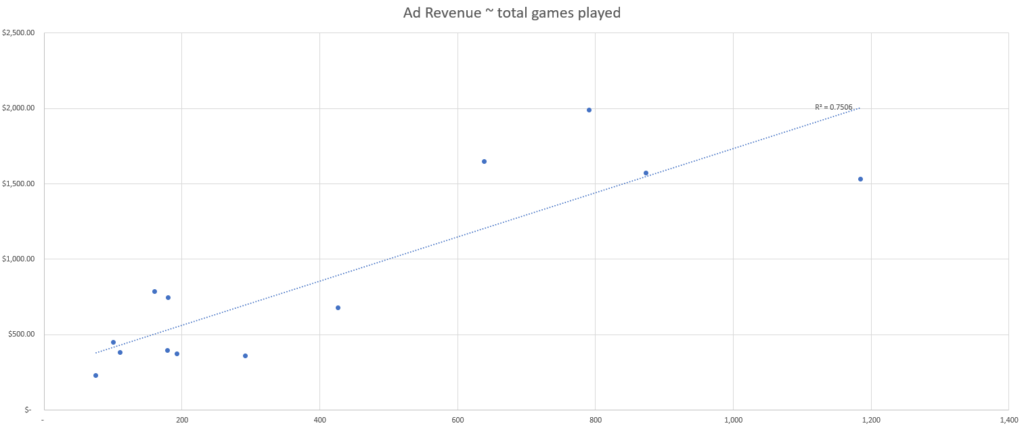
Sur la base de ces données simulées, nous pouvons voir que l’événement associé à la meilleure force de corrélation semble être le nombre d’utilisateurs actifs sur la base de notre métrique d’ajustement R-squared.
Ainsi, le point de données de notre ensemble qui explique le mieux les changements dans les revenus publicitaires est le nombre d’utilisateurs actifs, et nous devons donc utiliser le nombre d’utilisateurs actifs pour attribuer les revenus publicitaires canal par canal.
Étape 4
Une fois que vous avez sélectionné un KPI de comportement utilisateur, il est temps de calculer la marge de contribution.
Ensuite, multipliez la marge de contribution quotidienne de chaque canal par les revenus publicitaires cumulés générés chaque jour.
Ce processus nécessite que les données sur le comportement des utilisateurs soient mesurées par canal et accessibles tous les jours, de sorte que la marge de contribution de tous les canaux puisse être calculée avec les données de revenus de chaque nouveau jour.
Remarque : bien que nous n’incluions ici que quatre canaux publicitaires à des fins d’illustration, vous pouvez également inclure vos données organiques et d’autres canaux ici, afin d’attribuer et de relier entièrement les revenus quotidiens par rapport au comportement quotidien des utilisateurs.
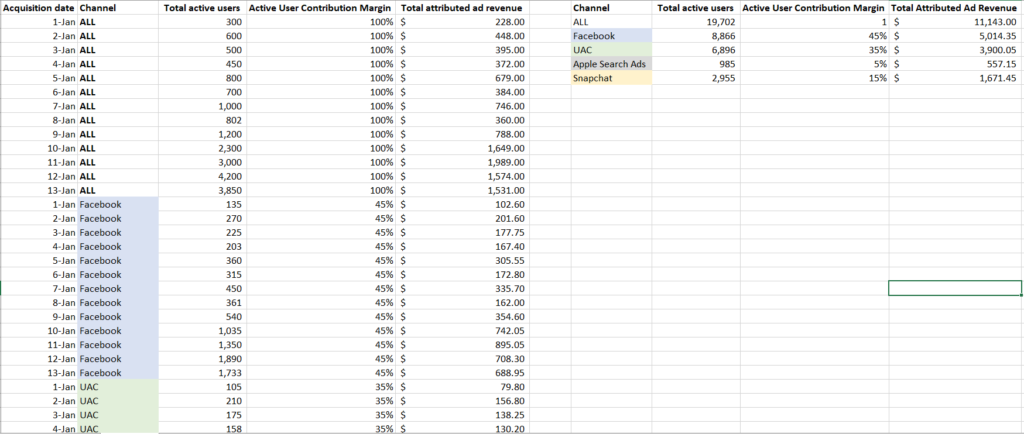
Ci-dessus, on peut voir les revenus publicitaires calculés générés par jour, par canal, ce qui permet d’estimer la rentabilité de chaque canal.
Notez que vous devrez revoir votre évaluation des KPI utiles pour l’attribution à mesure que les tendances de comportement, et les données de monétisation des revenus publicitaires évoluent, ou que de nouveaux points de données deviennent disponibles.
Par exemple, dans l’ensemble de données ci-dessus, nous pouvons voir un deuxième groupe de points de données vers la fin de la période (commençant approximativement le 10 janvier), où les revenus publicitaires par jour sont nettement plus élevés qu’au début du mois.
Cela se reflète dans le regroupement des données en haut à droite de chaque nuage de points, loin du groupe en bas à gauche.
Plus l’ensemble de données est complexe, moins cette simple évaluation de régression Excel sera précise, et plus il sera nécessaire d’appliquer une segmentation et une analyse plus rigoureuse.

Modélisation prédictive dans un monde centré sur la confidentialité
Vers une nouvelle réalité publicitaire
L’analyse prédictive vous permet d’augmenter l’audience potentielle de votre campagne, d’augmenter la LTV des utilisateurs et d’assurer une budgétisation plus efficace – à une époque où, dans certains cas, nous n’avons plus accès à des données de performance de type granulaire.
En créant différents groupes de caractéristiques comportementales, votre public peut alors être catégorisé non pas en fonction de son identité réelle, mais en fonction de son interaction avec votre funnel des ventes, à ses débuts. Cette interaction peut indiquer leur potentiel futur à générer une valeur significative pour votre produit.
La combinaison de facteurs clés d’engagement, de rétention et de monétisation, peut être corrélée à la compatibilité d’un utilisateur avec la logique LTV de n’importe quel développeur et fournir une indication de lapLTV (Predicted Lifetime Value) au tout début d’une campagne.
Machine learning – La clé du succès
Une application mobile peut avoir plus de 200 métriques disponibles pour la mesure, mais la plupart des spécialistes marketing n’en mesureront probablement qu’un maximum de 25. Une machine, en revanche, est capable d’ingérer toutes ces informations en quelques millisecondes et de les appliquer aux informations marketing et aux indicateurs de fonctionnalité des applications.
Un algorithme de machine learning pourra calculer tous ces indicateurs et trouver les bonnes corrélations pour vous. Ses calculs seront basés sur votre définition du succès, votre logique LTV, et l’appliqueront à une quantité importante de données pour trouver une corrélation entre les premiers signaux d’engagement et le succès éventuel.
Cela signifie que les annonceurs n’ont plus besoin de savoir QUI est l’utilisateur, mais plutôt de savoir À QUEL profil pLTV et quelles caractéristiques ils correspondent. Ce profil doit être aussi précis que possible et mis à disposition dès les premiers jours de la campagne. Il doit représenter les exigences LTV de l’annonceur pour qu’il soit considéré comme valide et exploitable.
En ce qui concerne les applications de eCommerce par exemple, l’application d’indicateurs tels que les achats précédents, la fréquence des achats, l’heure de la journée ou la progression dans le funnel de vente permet à l’algorithme de regrouper les publics généraux en cohortes très granulaires, et mutuellement exclusives.
Cela permet un ciblage et des messages plus efficaces, et finalement un ROAS plus élevé.
Tirer parti des prédictions LTV du cluster
L’analyse prédictive aide à réduire la période d’apprentissage de la campagne en utilisant les intégrations existantes pour fournir une prédiction LTV précise de la campagne.
En tirant parti du machine learning et en comprenant les données agrégées, l’analyse prédictive pourrait fournir une indication du potentiel de campagne sous la forme d’un score, d’un classement ou de toute autre forme d’informations exploitables dans les jours suivant son lancement, informant les marketeurs de son succès probable.
Par exemple, les machines d’une application de gaming ont constaté que les utilisateurs qui terminent le niveau 10 d’un jeu dans les 24 premières heures sont 50 % plus susceptibles de devenir des utilisateurs payants.
Grâce à ces informations, les spécialistes marketing peuvent soit réduire leurs pertes sur une mauvaise campagne qui ne fournit pas d’utilisateurs de qualité, optimiser si nécessaire, ou doubler la mise lorsque les premières indications montrent un profit potentiel, ce qui leur donne la possibilité de prendre des décisions rapides de pause, d’amplification ou encore d’optimisation.
Le défi SKAdNetwork
L’introduction de la réalité axée sur la confidentialité d’iOS 14 et du SKAdNetwork d’Apple a créé son propre ensemble de défis, limitant principalement la mesure des données au niveau de l’utilisateur dans l’écosystème iOS aux utilisateurs consentants.
Ceci est considéré comme la première étape vers un environnement publicitaire davantage axé sur la confidentialité des utilisateurs, et bon nombre des plus grands acteurs de l’industrie en ligne sont susceptibles de suivre la marche sous une forme ou une autre.
Ces changements limitent non seulement le volume de données disponibles, mais également la fenêtre de temps dans laquelle les spécialistes marketing peuvent prendre des décisions éclairées sur le succès ou non d’une campagne.
Bien que les algorithmes de machine learning puissent prédire rapidement quelles campagnes sont susceptibles d’offrir les clients les plus intéressants, d’autres limitations incluent les éléments suivants : manque de données en temps réel, pas de donnée ROI ou de LTV car il mesure principalement les installations, un manque de granularité puisque les données ne sont disponibles qu’au niveau de la campagne.
Alors, comment pouvez-vous diffuser des publicités pertinentes sans connaître les actions que chaque utilisateur effectue… ?
Vous l’avez deviné : Marketing prédictif basé sur le Machine learning. En utilisant des corrélations statistiques avancées basées sur des données historiques, sur le comportement des applications pour prédire les actions futures, les spécialistes marketing peuvent exécuter des expériences en utilisant des paramètres non personnalisés, tels que les signaux contextuels et la formation continue des modèles de machine learning.
Les résultats peuvent ensuite être appliqués à de futures campagnes et affinés au fur et à mesure que davantage de données sont collectées.

Meilleures pratiques pour créer des modèles de prédiction de marketing mobile
1. Nourrir la bête…
Lors de la création de modèles de données utilisés pour guider des décisions importantes, il est non seulement important de créer le meilleur système possible, mais également d’effectuer des tests continus pour garantir son efficacité.
Dans les deux cas, assurez-vous d’alimenter en permance votre modèle de prévision des bénéfices pour le maintenir formé sur les données les plus pertinentes.
De plus, vérifiez toujours si les prédictions de votre modèle se concrétisent sur la base de nouvelles observations, ou du moins s’en rapprochent.
Délaisser ces étapes peut ferait qu’un modèle doté d’une puissance de prédiction initiale pourrait ensuite dérailler en fonction de la saisonnalité, de la dynamique des macros enchères, des tendances de monétisation de votre application ou de nombreuses autres raisons.
En observant vos indicateurs avancés ou vos premiers repères et en recherchant des changements significatifs dans les points de données, vous pouvez également évaluer quand vos propres prévisions sont susceptibles de s’effondrer.
Par exemple, si votre modèle a été formé sur des données où le taux de rétention moyen au jour 1 variait de 40 % à 50 %, mais que pendant une semaine, le taux de rétention au jour 1 a chuté à 30 % -40 %, cela pourrait indiquer un besoin de ré-entraîner votre modèle.
Cela peut être particulièrement vrai étant donné que les quality signals des utilisateurs que vous avez récemment acquis ont changé, entraînant probablement des changements dans la monétisation et les bénéfices, toutes choses égales par ailleurs.
2. Choisir le bon KPI pour prédire la rentabilité
Vous avez le choix entre plusieurs options, chacune avec un ensemble de compromis en matière de viabilité, de précision et de rapidité pour produire des recommandations.
Lancez-vous et testez différents KPI (par exemple, plus ou moins de jours de ROAS ou de LTV) et utilisez un ou tous les éléments suivants pour comparer le pouvoir de prédiction des bénéfices de plusieurs KPI :
- Le R-squared
- Un ratio réussite/échec pour une prédiction satisfaisante
- Erreur absolue moyenne en pourcentage (MAPE)
Vous serez peut-être surpris de voir à quel point les mesures standard sont peu corrélées.
3. Segmentez vos données
La segmentation des utilisateurs en groupes plus homogènes est non seulement un excellent moyen d’améliorer le taux de conversion, mais également une méthode éprouvée pour réduire le « bruit » et améliorer la puissance prédictive de votre modèle.
Par exemple, l’application du même modèle, à la fois, aux campagnes basées sur les centres d’intérêt et aux campagnes similaires basées sur la valeur, pourrait entraîner des résultats moins performants. La raison en est que la monétisation et la durée de vie des utilisateurs sur chaque cible d’audience unique sont susceptibles d’être très différentes.
De plus, en créant différents groupes de caractéristiques comportementales, votre public peut alors être classé non pas en fonction de son identité réelle, mais en fonction de son interaction avec votre campagne à ses débuts. Cette interaction peut indiquer leur potentiel futur face à votre produit.
Par exemple, un développeur d’applications de jeu peut prédire la LTV potentielle de ses utilisateurs dans un délai de 30 jours. En d’autres termes : la période de temps jusqu’à la fin d’un tutoriel (engagement), le nombre de retours à l’application (rétention) ou le niveau d’exposition aux publicités au cours de chaque session (monétisation).
4. N’oubliez pas de prendre en compte le temps
La plupart des spécialistes marketing sont conscients des influences de la saisonnalité sur la décomposition des prédictions, mais le cycle de vie de votre application/campagne/audience/création peut également influencer la capacité de votre modèle à faire des prédictions précises.
Les tendances des coûts d’acquisition au cours de la première semaine du lancement d’une nouvelle application seront très différentes de celles du cinquième mois, de la deuxième année, etc. Tout comme les 1 000 premiers dollars dépensés dans un lookalike jusque-là inexploité seront différents du 10 000 et 50 000 dollars de dépenses investis dans le même lookalike (surtout sans changer le créative utilisé).

Points clés à retenir
Points clés à retenir
- La science de l’analyse prédictive existe depuis des années; elle est utilisée par les plus grandes entreprises du monde pour perfectionner leurs opérations, anticiper les changements de l’offre et de la demande, prévoir les changements gloqbaux et utiliser des données passées pour anticiper et se préparer aux événements futurs.
- Alors que nous nous dirigeons vers une nouvelle réalité centrée sur la confidentialité, nous devons adopter une nouvelle norme de mesure – une norme qui nécessite des délais de mesure plus courts et applique des indications potentielles d’utilisateurs anonymes pour la prise de décision.
- C’est exactement ce que fait la modélisation prédictive. L’introduction de cette technologie sophistiquée dans le paysage marketing et son application pour s’adapter à l’évolution de l’industrie est tout simplement primordiale.


