
空白を埋める:新しいモデルがSKANのプライバシーしきい値のペインをどう軽減するか


OSの広告主が頭を悩ませる原因の第1位は何でしょうか。
残念ながら候補はかなりあるのですが、Appleのプライバシーに関するしきい値は有力な候補です。
難点を簡単に思い出してみましょう。Appleのプライバシーしきい値は、マーケティング担当者がユーザー個人を特定したり、近づいたりすることを防ぐように設計されています。
どのように防いでいるのでしょうか?それは、SKAdNetworkのポストバックでコンバージョン値が送信されるかどうか、また、いつ送信されるかを決定することによります。しきい値を満たすには、特定のキャンペーンにおいて最低数のインストールが発生している必要があります。しきい値が満たされない場合、コンバージョン値はSKANポストバック で”null”と送信されます。しきい値が満たされている場合は、コンバージョン値が数字で送信されます。

プライバシーのしきい値はプライバシーを維持する上で重要ですが、適用された場合、マーケターはインストール後どのイベントが実行されたか、キャンペーン毎のパフォーマンスを知る術がありません。コンバージョン値がなければ、広告主はインストールの情報だけを受け取ることになり、インストール後のデータが一切なければ、その重みも価値もほとんどありません。
Appleは、実際のしきい値の条件を公表していないため、推測の域を出ないのがもどかしいところです。
部分的なデータを使用した誤った判断
コンバージョン値がnullの場合、マーケティング担当者はインストール後に発生したアクティビティや収益について、たとえ集計レベルであっても知ることができないことになります。欠落したデータは、eCPAとROASの計算ミスにつながる可能性があり、また、誤った最適化の試みと予算配分につながる可能性があります。
例を見てみましょう:
ネットワークAは、ネットワークBよりも、非常にエンゲージメントの高いユーザーを獲得することに優れています。ネットワークAを介して獲得したユーザーは、アプリ内でより多くの時間とお金を費やしており、時間の経過とともにロイヤルユーザーになる可能性が高くなります。
しかし、ネットワークAは1日のインストール率が低いため、ネットワークAでのインストールはプライバシーのしきい値を下回ることが多いです。その結果、それらのポストバックは、マスクされたコンバージョン値(コンバージョン値 = null)でレポートされるケースが多くなります。
一方、ネットワークBの毎日のインストール率は、プライバシーしきい値を満たすほど高く、ほとんどのコンバージョン値データはそのまま残ります。
コンバージョン値は、ネットワークBのインストールが中~低品質であることを示していますが、ネットワークAから取得した剥離データよりはまだましです。これは、ネットワークBの方が実際にパフォーマンスが高いという誤った印象を与えています。そのため、マーケティング担当者はこの結果に基づき、よりパフォーマンスが高いと見えてしまっているネットワークを最適化することを選択し、予算を無駄にしてしまうことでしょう。ですが、彼らを責めることができますか?これが非常に部分的なデータがもたらす代償です。
プライバシーに関するしきい値は、すべてのネットワークで平均11%の割合でデータホールを作り出しています(下のグラフ参照)。しかし、これは最悪の事態ではありません。SKANは、どのチャンネルがより良いパフォーマンスを出しているかをマーケティング担当者に知らせるために設計されたものです。マーケターは、表示されたデータが反対方向に向かうときに、どのようにして良い選択をすることができるのでしょうか。
最新のマーケティングニュースや専門家のインサイトを入手する
Nullコンバージョン値の簡単な歴史
2021年4月にATTとiOS 14.5が施行された時点で、Nullコンバージョン値は平均して全コンバージョン値の約8%を占めるようになりました。nulledコンバージョン値における急激なスパイクは2021年5月に発生し、その後、Appleがプライバシーしきい値アルゴリズムを変更した2021年10月に再び発生しました。この変化は急速に逆転し、数字は再び落ち着きを取り戻しました。
その後、広告主がどのように最適化し、Nullコンバージョン値率を下げようとも、平均11%程度で安定しており、Appleのアルゴリズム変更により、時々急上昇しています。
11%は、2021年10月に見られたピークの45%よりも確かに良いのですが、それでもマーケターが対処すべきデータの欠落は相当なものです。データの盲点に起因する推測は、マーケターを迷わせ、その過程で多くのフラストレーションを与えています。
単純な解決策で問題に取り組み、そして失敗する
私たちはプライバシーしきい値の現象を調査するために何ヶ月もかけて調査しました。Nullコンバージョン値を有意義なインサイトに変える最初の試みは、SKANのメカニズムに関する我々のエンジニアリングチームからの研究に基づいています。
その結果、コンバージョン値をマスクするかどうかの判断はインストール時に行われ、インストール後のユーザーの行動は考慮されないことがわかりました。つまり、Appleは、インストール時点でプライバシーしきい値に達したかどうかを判断します。
マスクされたコンバージョン値を持つユーザーとマスクされていないユーザーが同じように行動すると仮定すると、マーケティング担当者は同様の分布パターンを想定することができます。例を見てみましょう。
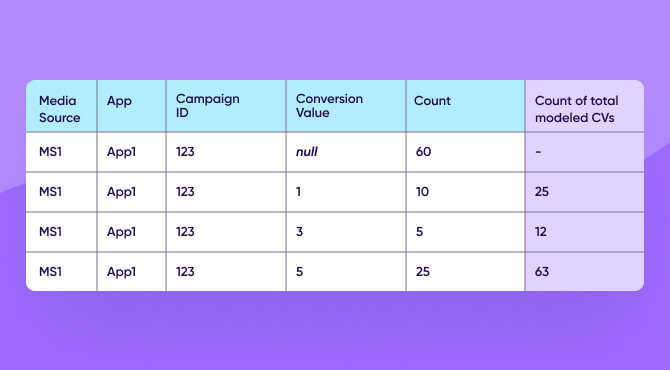
あるマーケターがキャンペーンを実施し、100件のインストールを獲得したが、そのうち60件はプライバシーしきい値を満たさず、コンバージョン値がマスクされている状態であったとします。
残りの40インストールは、コンバージョン値 1, 3, および5とレポートされました。
キャンペーン全体のこれらのコンバージョン値のそれぞれのコンバージョン値カウントをモデル化するために、マーケターが受け取った部分データ (40) はすべてのインストール (100) を表していると仮定します。
例えば、40件のインストール中、10件がコンバージョン値1を返した場合。10が40件の25%の場合、100の25%は25件のインストールです。
当初、私たちが提案したソリューションは、少し素朴で単純なものでした。実装が簡単で、理にかなっているのですが、2つの大きな欠点がありました。
- ポストバックの100%がマスクされた場合、推定されたコンバージョン値数はゼロになります。
- マスクされたコンバージョン値の割合が高い場合、推定のベースとなる部分的なデータにより、推定されたインストール数やイベント数が膨らんでしまうのです。
この単純なモデルでは痒いところに手が届かないし、真の価値を提供するには欠点が大きすぎることが明らかになったのです。
横からではなく、上を向いて答えを出すモデル
これらの欠点に対処するため、エンジニアリングチームはより高度な機械学習モデルを開発しました。この高度なモデルは、広告セットやキャンペーンごとのインストール数が限られている場合でも、広告セットレベルまで正確な結果を提供することができるのです。
これは、ベイズ型の階層的手法によって実現されています。統計テストを実行して、集計レベル(広告セット、キャンペーンなど) で分布を推定するために十分なデータがあることを確認します。十分なデータがない場合は、同じレベル以上の分布を使用します。
モデルの精度を保証するために、代表的なデータセットでモデルを学習し、学習に使用したのと同じデータセットのサブセットに基づいてモデルを検証しました。最後に、学習済みモデルの汎化能力をテストするために、別のデータセットを用意します。
その説明を読むだけでも口惜しいのですが、要するに、このモデルの精度を確保するために、徹底的にテストを行ったということなのです。最後に、モデル全体が設計された仮説を検証する時がきました。
テストデータセットとして、マスクされていないコンバージョン値のデータセットを使用します。データセットに含まれるコンバージョン値を積極的にマスクし、隠れたものを埋めるようにモデルを適用したのです。次に、機械モデル化コンバージョン値を除去したコンバージョン値と比較し、差を計算し、モデルは欠如コンバージョン値の88%を正確に予測しました。モデルの継続した検証を続けた結果、一貫して正確な結果が得られ続けたので、今日、このモデルを皆様へご案内できることを大変嬉しく思います。
推定された集計データの乗数効果
このモデルの優れた点は、Appleのプライバシー指標をそのまま維持しながら、マーケティング担当者の悩みを解決することです。マーケティング担当者がユーザーレベルのデータを明らかにすることはできませんが、より賢明な意思決定に役立つ集約的なインサイトを得ることができます。
欠落したデータを正確にモデル化(推定)することの影響は、それ自体を意味します。ただし、明白な範囲をはるかに超えるNullコンバージョン値をモデル化することには、追加の利点があります:AppsFlyerのSingle Source of Truth (SSOT) ソリューションにデータレイヤーが追加されました。マーケターは、SKANのポストバックによってコンバージョン値が無効になった場合でも、インストールとアプリ内イベントの重複を排除できるようになりました。要するに、コンバージョン値を正確にモデル化することで、iOSキャンペーンの最適化に取り組むマーケティング担当者にとっての第2の苦難が取り除かれるのです。
ベータ版でご利用いただいたお客様は、モデル化された収益とモデル化されていない収益を比較した場合、ROASが平均で約15%向上し、著しく正確な指標を確認することができました。
私たちは今後とも、プライバシーと正確性を両立させた、お客様にとって有意義なソリューションを提供できるよう、努力してまいります。AppleはSKAdNetworkに新しい機能を追加し続け、集約データに加えて高精度の機械学習技術を提供するために、常にモデルを更新しています。





