
MVPD (Multichannel Video Programming Distributor)

An MVPD is a multichannel video programming distributor providing bundled TV channels for purchase to consumers through cable, fiber, or satellite.
What is an MVPD?
A multichannel video programming distributor (MPVD) provides multiple broadcast TV channels on cable or satellite TV, and typically works on a subscription-based business model but can also offer video-on-demand options.
Examples of MVPDs include Xfinity, DISH Network, DirecTV, Spectrum, and Time Warner Cable.
What’s the difference between MVPD and vMVPD?
vMVPD stands for virtual multichannel video programming distributor, which provides both streaming content and linear content from broadcast channels in a single digital format.
vMVPDs compete with MVPDs through what’s known as “skinny bundles” — a lite version of a broadcast TV bundle offered at a lower cost. Skinny bundles are popular with Gen Z and millennials for their flexibility, with no annual contracts and ability to customize packages according to the customer’s preferences.
vMVPDs are able to keep their costs lower without the hardware investment required by MVPDs, and typically offer month-to-month subscriptions as well as smaller bundles of 30 to 100 channels.
How does MVPD work?
MVPD delivers linear TV programming to customers, primarily homes and businesses, and relies on a data transport infrastructure such as satellites, fiber, or coaxial cable to transmit the data to its destination.
MVPD uses a receiver box to connect the programming to a TV screen and manage controls through a video interface.
Under a traditional subscription model, customers sign a contract with an MVPD to provide TV programming for a set contract period such as one or two years.
| Example | Provider Type | Number of channels | Subscription model |
| DISH TV Everything Sports & Entertainment Package | MVPD | 240+ channels and 35,000 on-demand titles (ESPN, Disney, Hallmark, MLB Network, NBA Network) | 24-month contract |
| Sling TV (owned by DISH) Orange & Blue Package | vMVPD | 47 channels (CNN, TBS, ESPN, TNT, USA) | Monthly |
| DirecTV Choice Package | MVPD | 185+ live TV channels and 50,000 on-demand titles (NFL Network, NFL Sunday Ticket Max), GSN, OWN | 24-month contract |
| DirecTV Stream Choice Package | vMVPD | 90+ (ESPN, TNT, Nickelodeon, HGTV, MLB | Monthly |
| Network, NBA TV, etc.) | |||
| Netflix | OTT | 17,000+ show and movie titles | Monthly |
| Hulu + Live TV | vMVPD with OTT | Disney+, ESPN+, Hulu, and 75+ live TV shows | Monthly |
Cord-cutting and OTTs
In the past decade, many consumers have opted to “cut the cord” with MVPDs in favor of vMVPDs and OTT providers.
The number of homes without MVPD more than tripled in the US between 2014 and 2021, from 15.6 million to 50.4 million, with only 65.8% of US households paying for an MVPD or vMVPD subscription.
What is OTT?
“Over the top” is a streaming provider that offers media services via the internet.
OTT subscriptions worldwide passed one billion for the first time in 2020, growing 14% in 2021 to reach 1.3 billion.
OTTs provide access to non-linear, on-demand video content for a subscription fee that allows subscribers to control the time, content, and device on which they view videos, with content being available over smartphones, TVs, computers, smart TVs, or streaming sticks.
OTT providers have grown in popularity due to the increased control and flexibility for consumers, the lack of hassle with installing hardware, lower cost, and original content.
The first OTT original to win best picture at the Academy Awards, CODA by Apple+, demonstrates a rise in the volume and quantity of original content, With popular OTT providers including Netflix, Amazon Prime Video, Apple TV+, Hulu, Disney+, and HBO Max.
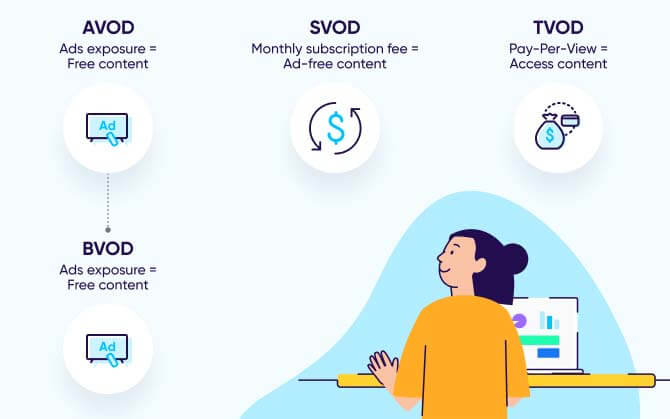
VOD vs. VPD
It’s easy to confuse the terms VPD (video programming distributor) and VOD (video on demand). VPD is the company providing the video services, whereas VOD is the service model, and as VPDs experiment with different business models and offerings, this distinction is important.
Both MVPDs and vMVPDs can offer VOD as a feature, either online or within an MVPD viewing system. Within VOD, there are multiple models including AVOD, BVOD, SVOD, and TVOD. Here are the most popular types of VOD, explained:
AVOD: Advertising video on demand
AVOD is a service offering a library of recorded video content with an advertising monetization model. While free to users, viewers must watch ads at intervals between content.
BVOD: Broadcaster video on demand
BVOD is on-demand video content from traditional broadcasters. BVOD is a subset of AVOD that also offers ad-supported streaming content. This content can include new as well as old movies and TV shows. Typically, it includes high-quality, professionally-produced content.
SVOD: Subscription-based video on demand
SVOD is a business model where customers pay a monthly fee to gain access to a library of on-demand video content, which they can view as much as they want.
TVOD: Transactional video on demand
TVOD is also known as pay-per-view, a model by which customers can pay a one-time transactional fee to watch an individual piece of video content.
Why virtual MVPDs are still relevant
With the sharp rise in OTT subscriptions, it’s a fair question to ask if MVPDs and vMVPDs will soon become obsolete.
Despite the fall of MVPD subscriptions and the increased appetite for non-linear TV programming, there are several reasons why MVPDs and vMVPDs are still relevant:
1. Live and exclusive programming
MVPDs still corner the market on live programming, with exclusive programming for events like the Olympic Games, Super Bowl, World Cup, and award shows.
While these big events are primarily sports and live programming, there is also a market for other types of unique programming.
Take, for example, the Oprah With Harry and Meghan special that aired on CBS. While the interview attracted more than 17 million viewers via the live broadcast, it also drew millions of new subscribers to Paramount+, CBS’ vMVPD service.
2. MVPDs are evolving to embrace the digital age
DISH Network innovated the vMVPD model with the launch of Sling TV in 2015. To meet changing consumer preferences, many other MVPDs followed suit with skinny bundles such as DirecTV’s DirecTV Now.
While the market may change, distributors have shown that they’re willing to experiment with different models to meet consumer demand.
3. Multiple subscriptions
Data shows that rather than paying for one large cable package, many consumers are willing to pay for multiple subscriptions to build the viewing options that they want.
A Comcast study found that vMVPD subscribers stream 128 hours of digital content a month, of which 50% is spent streaming OTT content outside of their vMVPD subscriptions. Unlike traditional cable, where households would have a single provider, the average household now subscribes to four VOD services.
Key takeaways
- The number of MVPD subscriptions has dropped steadily since the mid-2010s, while OTT and vMVPD subscriptions have exploded.
- While vMVPDs face challenges such as increasing programming costs, the business model is still in its infancy and is projected to grow in subscribers and maturity.
- Video-on-demand and all its variations (AVOD, BVOD, SVOD, TDOV) are an opportunity for MVPDs, vMVPDs, and OTT providers to diversify their offerings alongside traditional linear TV.
- Live and exclusive TV programming continue to attract big audiences and large revenues for MVPDs and vMVPDs.

Mobile marketing dictionary from A-Z
Thanks for your download!




