

Filling in the blanks: How a new model alleviates the pain from SKAN’s privacy threshold


Can you guess what the number one cause of headache for iOS advertisers is today?
Well, there are quite a few candidates, unfortunately, but Apple’s privacy threshold is a strong contender.
A quick recap of what the fuss is all about: The Apple privacy threshold is designed to prevent marketers from identifying or even coming close to identifying a unique user.
How is this done? By determining if and when a conversion value will be sent with an SKAdNetwork postback. A minimum number of installs needs to be associated with a certain marketing campaign in order for the threshold to be met. If the threshold is not met, the conversion value is sent as “null” in the SKAN postback. If it is met, then a numeric conversion value is sent.

While privacy thresholds are crucial in terms of maintaining privacy, the result, when enforced, is that marketers have no way of knowing which post-install events took place or how different networks performed. Without a conversion value, advertisers are left with install data alone, which carries very little weight or value without the much-needed post-install data.
The fact that Apple does not disclose the actual threshold makes it a frustrating guessing game.
Using partial data to make wrong decisions
A nulled conversion value means the marketer is blind to the activity or revenue generated after the install, even on the aggregate level. The missing data can lead to a miscalculation of eCPA and ROAS, and in turn, misguided optimization attempts and budget allocation.
Let’s take a look at an example:
Network A is outperforming Network B in driving highly engaged users to the app. Users acquired via Network A are spending more time and money in the app, and are more likely to become loyal users over time.
However, Network A has a lower daily install rate, meaning installs in Network A often fall short of the privacy threshold. As a result, their postbacks are often being delivered with masked conversion values (conversion value = null).
On the other hand, Network B’s daily install rate is high enough to meet the privacy threshold, leaving most of the conversion value data intact.
The conversion values are indicating moderate-to-low quality for Network B installs, but it’s still better than the stripped data we’re getting from Network A. This gives the false impression that Network B is actually performing better. A marketer may therefore choose to optimize for this result, effectively pulling budget from the better performing network. And could you blame them? That’s what the (very partial) data shows.
Privacy thresholds are creating data holes across all networks at an average rate of 11% (see graph below). But that’s not the worst of it: privacy thresholds nullify the purpose of SKAN – which is designed to inform marketers on which channel is performing better. How can marketers make good choices when the data they’re shown can steer them in the opposite direction?
It is important to note that with the release of SKAdNetwork 4.0 Apple has added another layer into the privacy threshold mechanism – a new type of “coarse” conversion value. Having the coarse conversion value as an additional step between the “null” and “fine” conversion values may help reduce null rate, but not eliminate it. For this reason we plan to add more capabilities to our model, including the ability to model coarse values into fine values.
Get the latest marketing news and expert insights delivered to your inbox
A brief history of the nulled conversion values
When the enforcement of ATT and iOS 14.5 began in April 2021, nulled CVs (conversion values) accounted for about 8% of all CV data, on average. A drastic spike in nulled CVs occurred in May 2021, and then again in October 2021 when Apple made a change to their privacy threshold algorithm. This change was quickly reversed and numbers settled back down.
Since then, the null CV rate has stabilized at around 11% on average regardless of action advertisers have taken to optimize and lower those rates, with occasional spikes due to algorithm changes by Apple.
While 11% is certainly better than the 45% peak we witnessed in October 2021, it’s still a significant amount of missing data for marketers to deal with; guesswork fueled by data blindspots is leading marketers astray and creating a lot of frustration in the process.
Trying (and failing) to tackle the problem with a simplistic solution
We spent months investigating the privacy threshold phenomenon. Our first attempt at turning nulled CVs into meaningful insights was based on research from our engineering team on the SKAN mechanism.
The team realized that the decision whether or not to mask the CV occurs during installation, with no regard to post-install user activity. In other words, Apple determines whether the privacy threshold has been reached at the point of installation.
Assuming users with masked CVs behave the same way as users with unmasked ones, marketers can assume the distribution patterns to be similar. Let’s take a look at an example.
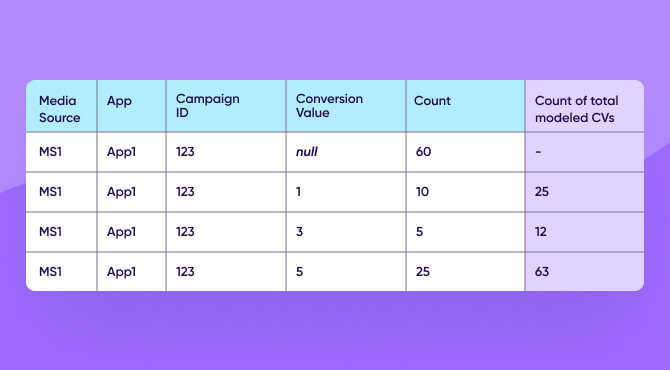
A marketer ran a campaign that resulted in 100 installs, of which 60 did not meet the privacy threshold and have masked CVs.
The remaining 40 installs returned conversion values 1, 3, and 5.
In order to model the conversion value count for each of these conversion values for the entire campaign, we assume the partial data the marketer received (40) represents all installs (100).
For example, 10 installs out of 40 returned conversion value 1. If 10 is 25% of 40, then 25% of 100 is 25 installs.
Initially, our suggested solution was a little naive and simplistic. It was easy to implement and made sense, but had two main drawbacks:
- When 100% of the postbacks were masked, the count of modeled CVs would be zero.
- When there was a high percentage of masked CVs, the partial data the model was based upon produced an inflated number of modeled installs and events.
It became evident that this simplistic model was not really going to scratch the itch, and the drawbacks were too significant to deliver real value.
A model that looks up—instead of sideways—for answers
To address these drawbacks, the engineering team developed a more advanced machine learning model: the advanced model is able to provide accurate results down to the adset level even when there is a limited number of installs per adset or campaign.
This is achieved through Bayesian hierarchical techniques. We run statistical tests to make sure we have enough data to estimate the distribution at the aggregate level (adset, campaign etc.). If we don’t have enough data, we use distributions at the same level or higher.
To ensure the accuracy of the model, we trained it on a represented dataset and validated it based on a subset of the same dataset that was used for training. Lastly, there was a separate dataset that was used to test the generalization ability of the trained model.
It’s a mouthful to even read that explanation, but the bottom line is that we tested the model extensively to ensure its accuracy. Finally, it was time to test the hypothesis the entire model was designed upon.
A set of unmasked CVs was used as a testing dataset. We proactively masked the CVs in the dataset and then applied the model to fill in the ones we’d hidden. We then compared the machine-modeled CVs to the ones we had removed, and calculated the difference.
The model accurately predicted 88% of the missing conversion values. This model continued to deliver consistent, accurate results when tested, and today we’re excited to share this model with our customers.
The multiplier effect of aggregated, modeled data
The beauty of this model is that it keeps the Apple privacy measures intact, while solving the pain point for the marketer. We’re not allowing marketers to uncover any user-level data, but are giving aggregate insights that can help make smarter decisions.
The impact of accurately modeling missing data speaks for itself. However, there is an additional benefit to modeling nulled conversion values that goes far beyond the obvious: AppsFlyer’s Single Source of Truth (SSOT) solution just got an added layer of data. Marketers can now de-duplicate installs and in-app events even in cases where the SKAN postback delivered a nulled conversion value. In essence, modeling conversion values accurately removes a second painful challenge for marketers working on iOS campaign optimization.
Our beta customers saw significantly more accurate metrics, with ROAS improving around 15% on average when comparing modeled revenue to un-modeled revenue.
We strive to continue to provide meaningful solutions for our customers where privacy and accuracy can go hand in hand. As Apple continues to add new features to SKAdNetwork, we’re constantly updating our model to deliver highly-accurate machine learning technology on top of aggregate data.


