Desenvolvendo a solução de análises preditivas da AppsFlyer


Em um mundo no qual a privacidade é a maior preocupação dos profissionais de marketing, o futuro pertence às análises preditivas.
E o futuro é agora.
A AppsFlyer tem trabalhado em desenvolver uma solução de análises preditivas desde o final de 2019, muito antes da privacidade se tornar um assunto tão em alta.
A introdução dos insights preditivos à estrutura tecnológica dos desenvolvedores de aplicativos pode oferecer aos clientes da AppsFlyer uma vantagem competitiva inigualável, além de trazer melhorias a diversos produtos da AppsFlyer, desde a Incrementalidade até a proteção contra fraudes.
A implementação desses insights começou com as previsões do lifetime value (LTV) das campanhas – nas quais o valor da campanha era estimado logo no início, acabando com o tempo de espera até que os resultados fossem obtidos.
Definindo a matrix do lifetime value (LTV)
O LTV de cada campanha normalmente é definido nas semanas seguintes à instalação de um app, enquanto que decisões sobre a UA são feitas o tempo todo, com base informações atuais. Isso significa que qualquer decisão, em qualquer momento, carrega determinado nível de incerteza sobre o LTV.
Um gerente de UA comum poderia lançar uma campanha e esperar pelos dados inicias de LTV do usuário para fazer escolhas acerca da otimização. Isso pode demorar até 30 dias ou, em muitos casos, mais. Utilizar ferramentas de análises e de BI avançada podem reduzir esse período para cerca de 10-15 dias.
No entanto, esses 10 a 15 dias ainda são muito. O nosso objetivo é acabar com esse período de espera (o “período de incertezas“) ao longo do qual as campanhas perdem dinheiro enquanto esperam por resultados. Para isso, definimos um ambicioso objetivo de oferecer insights preditivos sobre o LTV do usuário para o 30º dia de campanha, com base nas primeiras 24 horas de engajamento do usuário.
Mas como uma única fórmula de LTV pode ser aplicada à variedade infinita de cálculos de LTV utilizados pelos clientes da AppsFlyer?
Após conduzir uma pesquisa de mercado cuidadosa, o nosso time resumiu as possibilidades em três principais pilares, que contém os aspectos-chave para o processo de tomada de decisões de LTV na atividade de aquisição de usuários:
- Retenção: mensurar por quanto tempo se espera que um usuário utilize o app
- Engajamento: analisar o nível de engajamento de um usuário com o ambiente do app
- Monetização: classificar a potencial receita gerada por um usuário por meio de anúncios, compras e mais
Cada um desses pilares é mensurado em escalas diferentes então, primeiro, tivemos que padronizá-los. Para isso, decidimos aplicar um sistema de classificação relativa, que associa cada pilar a uma previsão exclusiva de classificação, que vai de 1 a 9.
Além disso, considerar o custo da campanha é fundamental, ou seja, temos que mensurar o LTV de um usuário com relação ao custo de aquisição desse usuário. Embora a previsão de custo não seja necessária por ser um valor fixo, ainda temos que classificá-la para que ela se adeque ao padrão do sistema.
Criando uma solução de acordo com os recursos disponíveis
Esse foi o momento ideal para começar a explorar os dados disponíveis e identificar os pontos de dados certos que podem ser transformados em rótulos (labels) e recursos de aprendizado de máquina.
Percebemos que, independente da abordagem usada, teríamos que incluir um design multi-usuários, ou seja, uma solução que acomodasse o maior número possível de clientes da AppsFlyer, apesar das diferenças inerentes entre verticais, uso, popularidade e modelos de negócios.
Inicialmente, nos concentramos em pontos de dados que estavam amplamente disponíveis para todos os clientes AppsFlyer. Fatores-chave como recência, frequência de uso, compras in-app e receita de anúncios no aplicativo eram os componentes “óbvios” na lógica de monetização de qualquer aplicativo.
Os eventos in-app da AppsFlyer são um excelente exemplo desses pontos de dados, pois todos os clientes são encorajados a utilizá-los.
Com os eventos in-app, a AppsFlyer sempre ofereceu flexibilidade aos seus clientes – tanto em tempo (quando um evento deve ser acionado / depois de quais ações), e em nomes de eventos de conteúdo ou quaisquer outros parâmetros que merecem ser relatados.
Por um lado, isso significa que os proprietários de aplicativos podem adaptar esses eventos, para que eles correspondam às suas próprias necessidades específicas, oferecendo insights valiosos e relevantes em seu ecossistema.
No entanto, algumas dessas informações não podem ser transformadas em um recurso ou rótulo de aprendizado de máquina, pelo menos não sem uma camada de mediação que traduziria as informações que um evento in-app transporta para a categoria correspondente de componente LTV.
Decidimos lidar com esse problema de ambos os lados e desenvolvemos um processo que analisa dados de eventos históricos do cliente e determina a “hierarquia” probabilística de eventos.
Em paralelo, recomendamos que os nossos clientes mapeiem eventos para as categorias correspondentes com base na importância desses eventos para a sua própria lógica de LTV.
A combinação desses métodos nos deu o insight necessário para o uso de dados históricos do cliente e para a criação dos nossos conjuntos de dados de treinamento de machine learning.
Validação do processo
Depois que conseguimos validar com os nossos parceiros de design que os pontos de dados escolhidos eram ideais para descrever o LTV do usuário, passamos a inspecionar como eles distribuíam dentro do nosso conjunto de dados escolhido. A distribuição de recursos ou alvos/destinos dentro do conjunto de dados é muito importante para garantir a precisão do machine learning.
Trabalhar com um conjunto de dados esparsos, no qual a maioria dos “alvos” se distribuem ao redor de um único ponto, não gerará grandes resultados. Por exemplo, se um desenvolvedor de aplicativos relata apenas o nível de progresso quando um usuário chega ao nível 500, mas na realidade 99.9% de todos os usuários do app nunca chegarão a esse nível, acabamos com uma distribuição de recursos/alvos que não pode ser usada para a nossa previsão de engajamento.
Este é um ponto de decisão crucial no processo de integração de qualquer aplicativo – se ele não fizer um bom uso da AppsFlyer (com o envio de eventos in-app, oferecendo informações de compra e eventos de receita de anúncios, etc), não seremos capazes de criar um modelo de previsão confiável e suficientemente preciso. Assim, o cliente deve aproveitar ao máximo os recursos da AppsFlyer antes de fazer a integração.
Depois de garantir o bom funcionamento do processo que criamos para transformar os dados brutos do cliente nos componentes de LTV que gostaríamos de prever (para aplicativos elegíveis), nos concentramos em garantir que o sistema de classificação seja ideal – de forma que ele descreva com precisão os dados analisados (em termos de desvio padrão e distribuição) e seja o mais benéfico para clientes que precisam tomar decisões de UA com clareza e confiança.
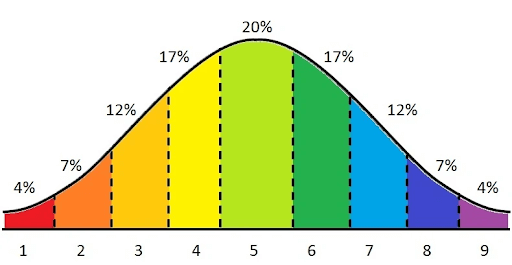
Optamos por implementar a pontuação de Stanine com pontuações na escala de 1-9. Esse método é conveniente tanto por suas diferenças de pontuação (que não é tão pequena de forma que a diferença não faça sentido, e nem muito grande de forma a refletir grandes diferenças entre as campanhas) e sua distribuição padrão de dois, o que permite um cálculo fácil da porcentagem da campanha.
Em alguns casos, quando a distribuição de dados não era “perfeitamente normal”, mas se assemelhava à distribuição normal, usamos a transformação Box Cox para redistribuir a população-alvo para uma distribuição mais próxima do normal.
A natureza da cronologia do LTV foi a base para a nossa hipótese de que uma solução baseada em RNN provavelmente poderia gerar os melhores resultados. Depois de alguns testes e de muita investigação, decidimos usar o Tensorflow como nosso framework de machine learning e passamos a desenvolver o nosso algoritmo usando a API Keras.Sequential. Depois, mudamos para a API Funcional que permitia mais flexibilidade, mas era mais complexa.
Vamos fazer uma análise mais detalhada sobre o processo de unir todas as peças que tornaram essa solução possível.
Desenvolvendo o produto
Decidimos desenvolver nosso sistema de produção utilizando o Amazon SageMaker para inferência em tempo real. O Amazon SageMaker oferece uma solução de endpoint multiusuários em tempo real, que pode ser personalizada para funcionar em várias estruturas de ML e oferece suporte a algoritmos personalizados como o que criamos.
“Este é um ótimo exemplo de como o Amazon SageMaker pode ser usado para simplificar e agilizar o desenvolvimento de produtos baseados em machine learning em escala. O Amazon SageMaker ofereceu à AppsFlyer a flexibilidade necessária para utilizar os seus próprios algoritmos de ML e ainda aproveitar as vantagens de um serviço gerenciado. O SageMaker é utilizado para treinar, otimizar e implementar vários modelos de machine learning de forma escalável, automatizada e econômica. Além disso, graças ao uso do Multi-Model Endpoints, a AppsFlyer foi capaz de reduzir o fardo do gerenciamento da implementação de vários modelos e atualizações, copiando-os com facilidade para o S3.”
Orit Alul e Chaitanya Hazarey, Arquitetos de Solução do AWS
Também decidimos utilizar os serviços gerenciados da AWS, como AWS Lambda, Amazon SQS e AWS DynamoDB para acelerar o processo de desenvolvimento, mantendo a escalabilidade e estabilidade que nosso produto exigia.
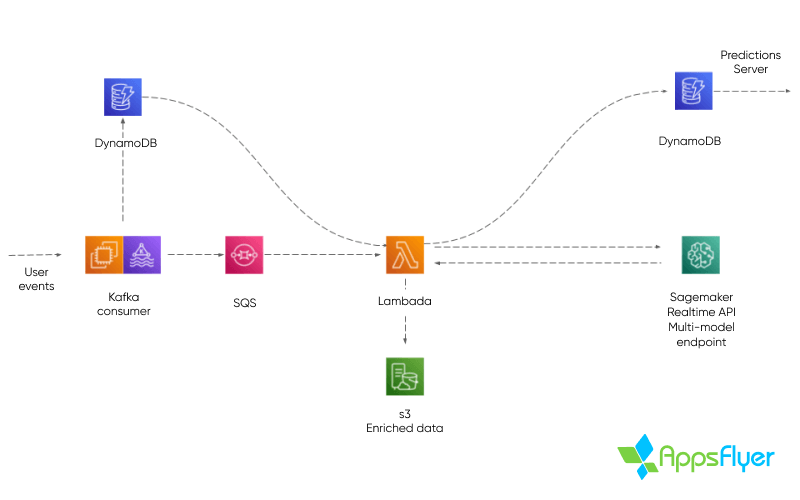
O sistema de produção ingere eventos em tempo real de SDKs do cliente, que chegam por meio de tópicos Kafka. Os dados do evento e os metadados do usuário são armazenados nas tabelas do DynamoDB, e um processo de decisão se aplica para cada evento consumido.
Se uma inferência ocorrer após o evento atual, quando há uma decisão sobre uma inferência, os metadados “previstos” do usuário são despachados para uma função Lambda via SQS. Os dados do evento são carregados na função Lambda, transformados para ML e enviados ao SageMaker para inferência. Assim que um resultado é recebido, ele é armazenado em outra tabela do DynamoDB.
Esse processo gera pontuações do usuário que podem ser solicitadas pelo SDK do cliente como valores de conversão de SKAdNetwork a qualquer momento, e são constantemente atualizados para maximizar a precisão das previsões.
Treinando o modelo
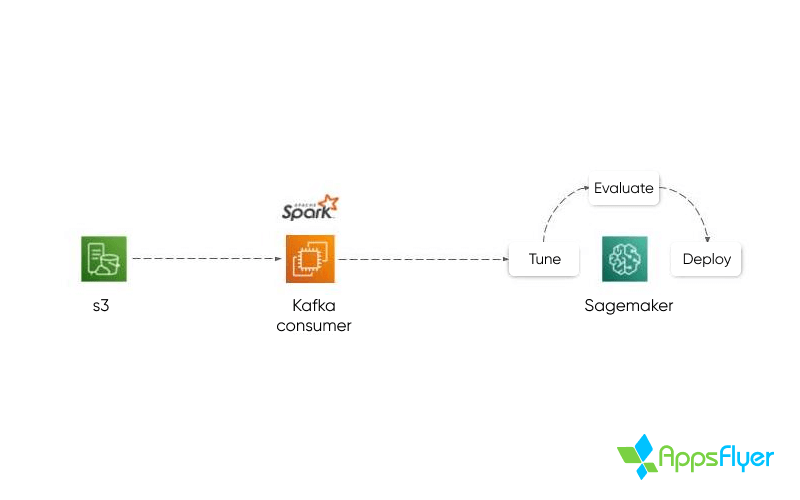
Antes de integrar um novo aplicativo ao Predict, é necessário um período de treinamento no qual todos os dados históricos primários do aplicativo são analisados e revisados usando o Amazon SageMaker. O processo tem como objetivo identificar e modelar diferentes tipos de correlações e se repetirá até que níveis satisfatórios de precisão do modelo sejam alcançados.
A precisão do modelo é revisada usando estatísticas múltiplas; MAE – média absoluta de erros do modelo (por categoria), RMSE – raiz quadrada média de erros e Kappa de Cohen para garantir a validade e integridade do modelo.
Os ajustes necessários são feitos no modelo, introduzindo pontos de dados adicionais, modificando pesos relativos de eventos específicos e rótulos. Isso tudo foi feito para aperfeiçoar o modelo antes do lançamento.
Assim que a integração for concluída e as campanhas forem lançadas, novos usuários começarão a baixar e a se engajar com o aplicativo, gerando novos dados por meio do SDK da AppsFlyer.
O Predict calcula a pontuação de benefício de um usuário com base nos três pilares de engajamento, retenção e monetização. Essa pontuação de benefício é comparada ao custo da campanha, gerando uma pontuação abrangente e acionável.
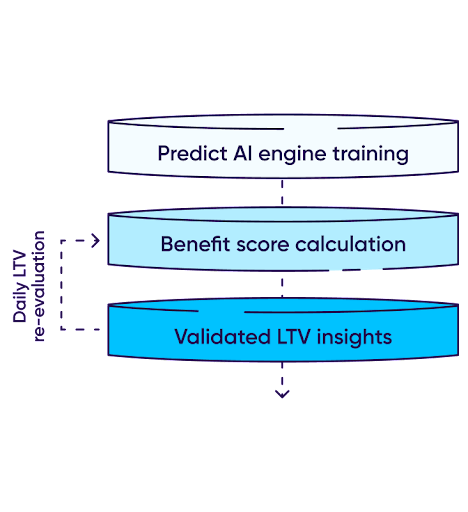
O processo de reavaliação da pontuação é repetido de forma consistente durante a janela de mensuração do usuário (geralmente 24 horas) com o objetivo de produzir uma classificação preditiva precisa.
Assim como ocorre em outros produtos da AppsFlyer, a infraestrutura do AWS nos permite operar esse processo complexo em grande escala. Além disso, produtos como o Amazon SageMaker torna possível que isso seja feito em um modelo multiusuários, o que possibilita o desenvolvimento e a operação de modelos preditivos exclusivos em diferentes aplicativos e desenvolvedores de maneira isolada.
A análise preditiva não apenas oferece vantagem competitiva por meio da capacidade de prever o que vem pela frente, como também possibilita um grande avanço na maneira como otimizamos e comercializamos nossos produtos.
Não importa mais quem é o usuário, apenas o que o seu comportamento pode nos dizer.





