
ВРЕМЯ ЧТЕНИЯ: 23 МИН.
Руководство маркетолога по данным первой стороны
Попробуйте поискать

")
После того как мы с дизайн партнерами проверили оптимальность выбранных нами точек данных для наилучшего описания LTV пользователя, мы проверили их распределение в выбранном датасете.
Распределение функций или целей в наборе данных имеет большое значение для точного машинного обучения.
Работа с неполным набором данных, где почти все «цели» распределены вокруг одной и той же точки, не даст хороших результатов.
Например, если разработчик приложения сообщает об уровне прогресса, только, когда пользователь достигает уровня 500, но по факту 99,9% всех пользователей приложения никогда не достигнут этого уровня, мы получим распределение функций / целей, которые невозможно будет использовать для прогнозирования вовлеченности.
Это важный момент принятия решения в процессе интеграции любого приложения – если приложение не пользуется преимуществами AppsFlyer в значительной степени (отправка событий внутри приложения, предоставление информации о покупках, событий, связанных с доходом от рекламы и т.д.), мы не сможем создать модель прогнозирования, которая будет надежной и достаточно точной.
В этом случае от клиента требуется более широкое использование возможностей AppsFlyer еще до начала работы с Predict.
Убедившись в том, что процесс, который мы создали для преобразования сырых данных клиента в компоненты LTV, которые мы хотим спрогнозировать, работает хорошо, мы сосредоточились на том, чтобы проверить, что балльная система, которую мы хотим использовать, подходит для нашего случая, а именно, что эта система точно описывает анализируемые данные (с точки зрения допустимого отклоненияи распределения), и может быть наиболее полезной для наших клиентов для принятия оптимальных решений по UA.
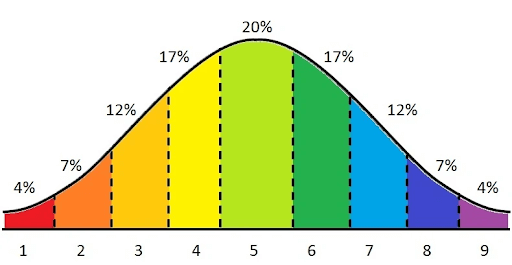
Мы решили использовать систему Станайн с оценками по шкале от 1 до 9.
В некоторых случаях, если распределение данных было не «абсолютно нормальным», мы использовали преобразование Бокса-Кокса, чтобы перераспределить данные ближе к нормальному графику. Зависимая от времени природа LTV подтолкнула нас к гипотезе о том, что наилучшие результаты мы получим в решении на основе Рекуррентной нейронной сети (RNN).
После некоторого тестирования и исследования мы решили использовать Tensorflow в качестве фреймворка машинного обучения и начали разработку нашего алгоритма с использованием Keras.Sequential API, позже перейдя к функциональному API, который обеспечил большую гибкость.
Мы решили построить нашу производственную систему с использованием Amazon SageMaker. Sagemaker предоставляет многопользовательское решение в реальном времени, которое можно настроить для работы с различными фреймворками машинного обучения, а также он поддерживает настраиваемые алгоритмы, как те, что разработали мы.
“ Это отличный пример того, как можно использовать Amazon SageMaker для упрощения и ускорения масштабной разработки продуктов, основанных на машинном обучениии. Amazon SageMaker предоставил AppsFlyer гибкость, позволяющую внедрять собственные запатентованные алгоритмы машинного обучения и при этом пользоваться преимуществами управляемого сервиса. SageMaker используется для обучения, оптимизации и развертывания нескольких моделей машинного обучения масштабируемым, автоматизированным и экономичным способом. Кроме того, благодаря использованию многомодельных конечных точек AppsFlyer удалось снизить нагрузку на организацию развертывания и обновления нескольких моделей, просто скопировав их в S3”.
Orit Alul and Chaitanya Hazarey, AWS Solutions Architects
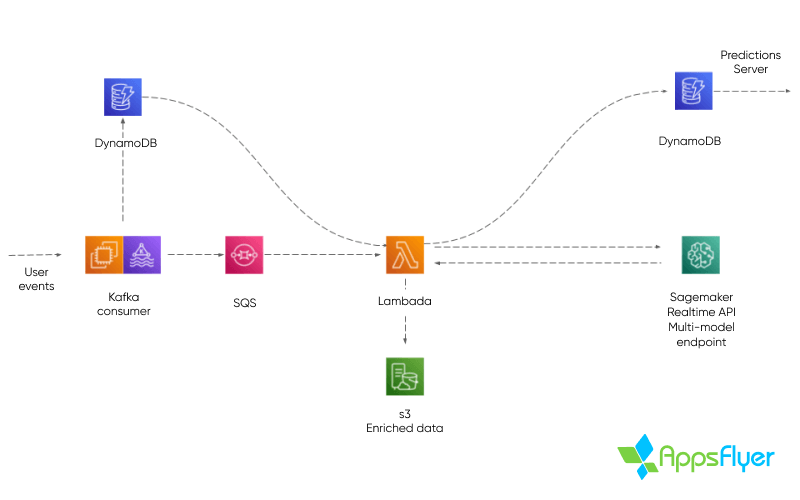
Мы также приняли решение использовать сервисы AWS, такие, как Lambda, SQS и DynamoDB, чтобы ускорить процесс разработки, продолжая при этом увеличивать необходимые масштабируемость и стабильность продукта.
Производственная система регистрирует события в реальном времени из клиентских SDK, попадающих через топики Kafka. Данные о событиях и пользовательские метаданные хранятся в таблицах DynamoDB, а процесс принятия решения выполняется по каждому событию. Если логический вывод происходит после текущего события, когда делается вывод, «предсказанные» метаданные пользователя отправляются в лямбда-функцию через SQS.
Затем данные события загружаются в функцию Lambda, преобразуются для машинного обучения и отправляются в Sagemaker для составления вывода. После получения результат сохраняется в другой таблице DynamoDB. Этот процесс генерирует баллы пользователей, которые могут запрашиваться с SDK клиента как значения конверсии SKAdNetwork в любое время, и часто обновляются с течением времени для достижения максимальной точности прогнозов.

Перед интеграцией нового приложения с Predict требуется период обучения, в ходе которого все исторические данные приложения анализируются и проверяются с помощью AWS Sagemaker. Этот процесс предназначен для выявления и моделирования различных типов корреляций и будет повторяться до тех пор, пока уровень точности модели не будет удовлетворительным.
Точность модели проверяется с помощью нескольких статистических данных; MAE – средняя абсолютная ошибка модели (по категории), RMSE – среднеквадратичная ошибка и Каппа Коэна для обеспечения достоверности и целостности модели.
В модель вносятся необходимые корректировки путем введения дополнительных точек данных, изменения относительных весов и меток конкретных событий. Все это делается для усовершенствования модели перед запуском кампании. После завершения интеграции и запуска кампании новые пользователи начнут загружать приложение и взаимодействовать с ним, генерируя новые данные с помощью SDK AppsFlyer.
Predict рассчитывает оценку пользователя (user’s benefit score) на основе 3 параметров: вовлеченности, удержания и монетизации. Эта оценка (benefit score) рассчитывается в сравнении со стоимостью кампании.
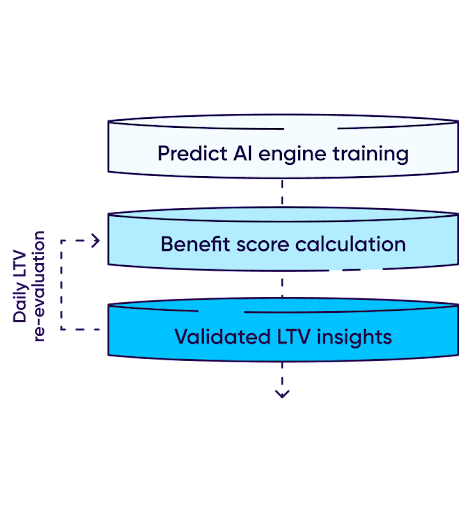
Процесс переоценки баллов постоянно повторяется в течение окна измерения пользователя (обычно 24 часа) с целью получения точного балла.
Как и в случае с другими продуктами AppsFlyer, инфраструктура AWS позволяет нам выполнять эту сложную операцию на должном уровне, а такие продукты, как AWS Sagemaker, дают нам возможность работать с ней в многопользовательском формате, благодаря чему мы можем создавать и использовать уникальные прогностические модели для разных приложений и разработчиков в одном месте.
Предиктивная аналитика не только дает нам значительное конкурентное преимущество за счет способности предвидеть, что нас ждет впереди, но и обеспечивает значительный скачок вперед в том, как мы оптимизируем и продвигаем наши продукты. Идентификация пользователя больше не имеет значения, важно то, что может сказать нам его поведение.





