
Flying under the radar: Mobile ad fraud


Apple’s App Store has long been regarded as the safest environment for users to install apps. Any developer looking to submit their app to the store must go through a strict vetting process which is designed to protect users from code that puts user privacy at risk such as malicious adware or any other type of harmful content that could taint Apple’s clean image.
The term “walled garden” has justified its name.
When it comes to mobile attribution fraud, it has been always been assumed that known fraud attacks, which rely on malicious SDKs and code on the user’s device, were considered irrelevant for iOS devices thanks to this strict vetting process.
Until recently…
New research by Snyk, the open source security company, revealed a method where app developers can “hide” a piece of their code from Apple’s strict inspections.
“Our research team discovered that a popular iOS Advertising SDK, used by over 1,200 apps in the AppStore, with more than 300 Million downloads combined — injects code into standard iOS functions within the application and is capable of intercepting all HTTP requests made by the app. This gives the SDK access to a significant amount of data including private user information, cookies and authentication tokens, and works to steal potential revenue from other ad networks the application may be using.”
The case discovered by Snyk was seemingly carried out to perform a sophisticated type of mobile attribution fraud; however, the way this scheme came to play was a real cause for concern.
Hidden sophistication
The specific case mentioned above detected a piece of code that was masked when running through Apple’s review. The code was deliberately designed to turn-off once it identified that it was running in a simulated environment, if there was a debugger attached, if the phone was rooted, or if a VPN was enabled.
This type of sophisticated masking created a code sequence which is extremely difficult to detect, and likely the reason why Apple missed it during their meticulous inspections.
The code itself was placed on various iOS apps as a standard ad network SDK with the intention of harvesting information from ad clicks generated by users.
The potential applications of such a security loophole would mean that similar methods for harvesting sensitive user-data are most likely already in use across other apps for reasons that go beyond attribution fraud.
While harvesting user-data for other purposes, the case presented is believed to have been mainly focused on generating revenue by way of mobile attribution fraud, applying an evolved form of install hijacking.
Report
The state of mobile ad fraud – 2020 edition
The evolution of install hijacking
Install hijacking is a form of fraud in which a media source steals credit for an app install from another media source.
This is often carried out by using fake clicks that are artificially injected into the user journey, with the purpose of tricking last-click attribution models into its associated last-click report to the fraudulent source. The closer the click will be to the original ad click, the harder it is to distinguish between them and detect it as fraud.
These clicks can be generated through malware located on another app on the user’s device, which is triggered once a new app install is identified.
This new version of install hijacking behaves in a similar way, in that it too relies on a piece of malware. However, this malware is triggered by clicks, rather than an initiation of an install. The mobile malware can scan through all clicks coming through the user’s device, and generate a fake click that is populated with the fraudster’s details to steal credit for any install that may have been driven by those clicks.
Beyond the malicious code’s sophisticated masking, this new fraud version can be extremely elusive and difficult to detect, especially when it is done “correctly”, as it attempts to bypass common click-time-to-install (CTIT) based detection algorithms.
Let’s examine a few familiar distribution patterns to see how this plays out.
Our first point of reference will be Network A’s CTIT distribution. Network A delivers clean and fraud-free traffic.
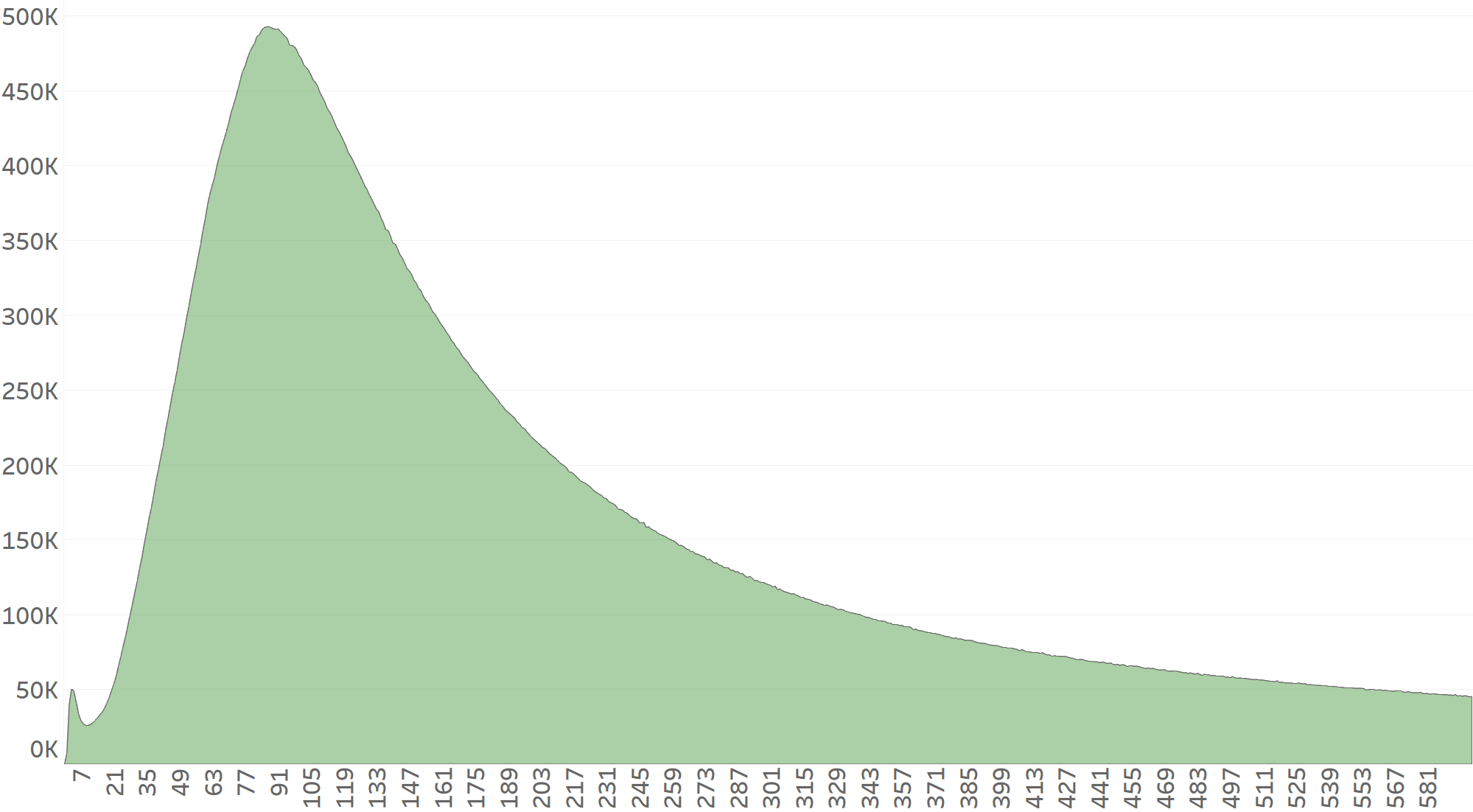
Example 1: A click is injected 10 seconds after a legitimate click
Now let’s assume that Network B detects each and every click reported by Network A and generates its own click exactly 10 seconds after each click.
Network B’s CTIT distribution will now be divided into 2 sections:
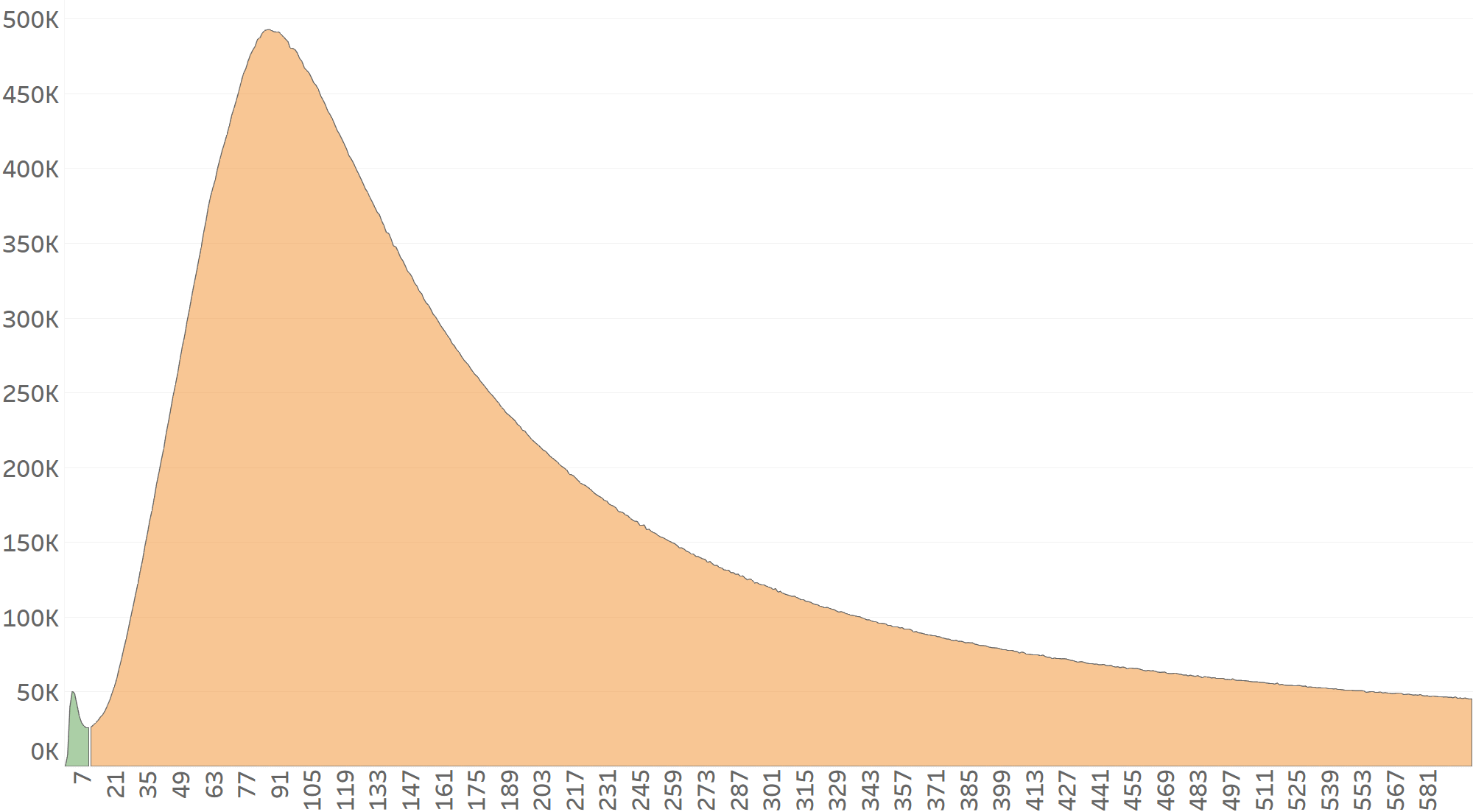
The installs with CTIT under 10 seconds are attributed to Network A (green), while anything coming in at 10+seconds will be attributed to Network B (orange).
Network B’s CTIT distribution will be slightly skewed to the right, as Network B’s CTIT distribution effectively begins at the CTIT=10 mark. This makes it difficult for standard algorithms to detect. However, CTIT is not AppsFlyer’s only fraud indicator. By analyzing the CTCT distribution (Click-To-Click-Time) we can also identify time difference abnormalities between the two following ad-clicks.
Using CTCT as a continuous variable, allows us to create a visual representation of its distribution in-order to detect anomalies, just like we do with CTIT. When reviewing Network B’s CTCT distribution, activity spikes that could indicate fraud become more visible.
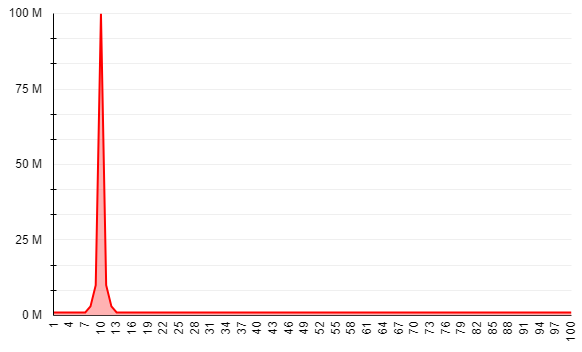
In order to remain undetected, Network B won’t actually generate a click for 100% of Network A’s clicks as this will attract too much attention.
Alternatively, Network B will generate lower click volumes in order to remain unnoticed.
Example 2: A fake click injected 30+ seconds after a legitimate click
In an attempt to “normalize” it’s activity, Network B will generate its fake clicks ~30 seconds after Network A’s original click.
By doing so, Network B will “sacrifice” some of the potential stolen activity. The upside is that the CTCT graph created for these attributed installs will not look as “bad” as before, which may not be significant enough for standard detection algorithms to detect.
However, in this case, the CTIT distribution will be heavily skewed to the right, which will trigger Protect360’s MLE (Maximum Likelihood Estimation) algorithm to detect the pattern as fraudulent, as seen in the graph below (Network B’s CTIT begins at the 30 seconds mark).
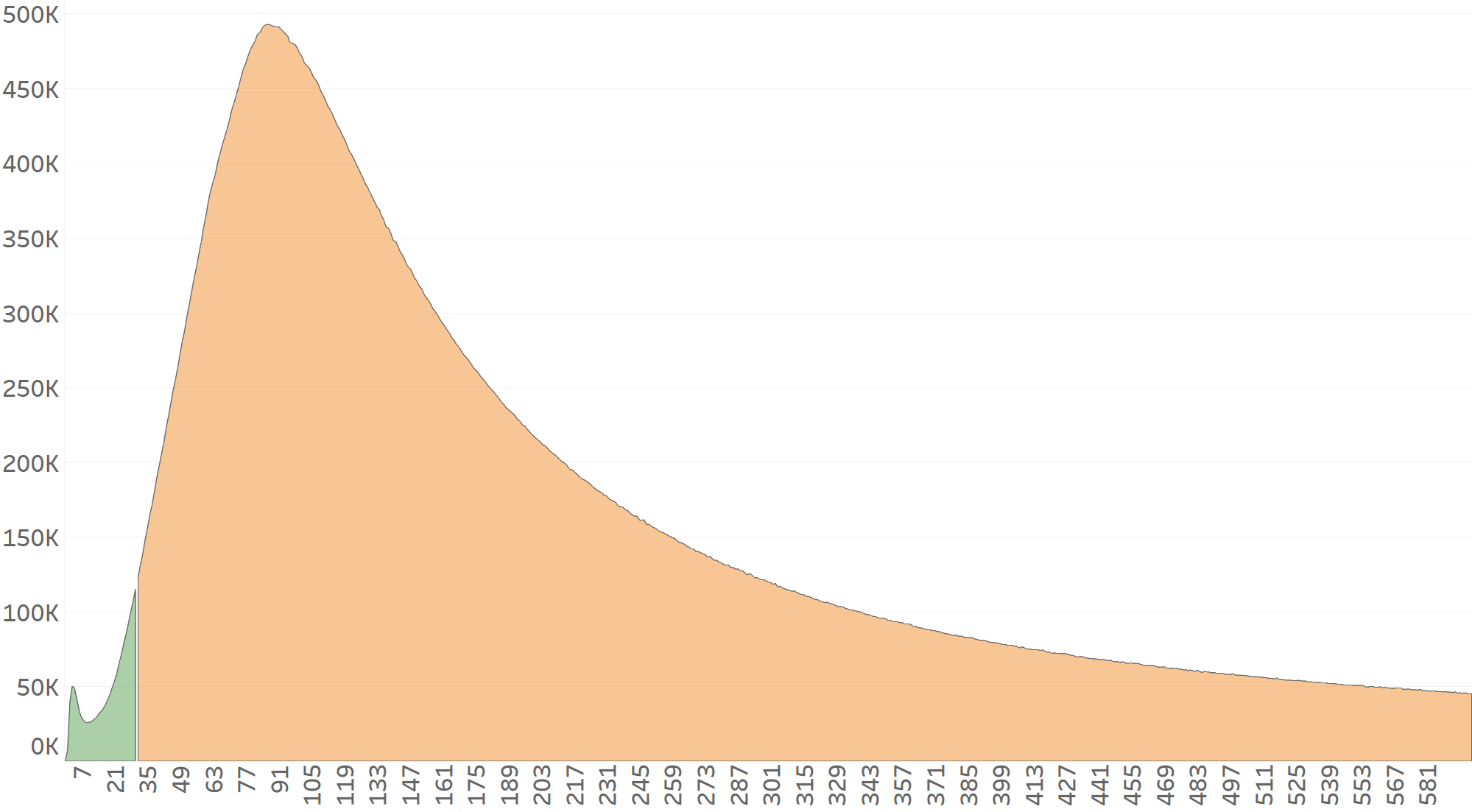
MLE enables Protect360’s detection algorithms to identify behavior anomalies and curve differences that can’t be seen by the naked eye (no matter how professional it may be).
Our detection is carried out by comparing each app’s unique behavior pattern to its own common behavior trends across several variations. Unlike cases where all apps are measured under similar benchmarks, this allows us to compare apples to apples and avoid false detection.
Get the latest marketing news and expert insights delivered to your inbox
Key takeaways
Fraud identification cannot rely on just one parameter or set of parameters. Nor can we assume that a specific environment, as safe as it may be, is truly impervious to specific types of fraud or fraud in general.
A solid anti-fraud solution is an adaptive one. One that can creatively use the data points and measurement at its disposal to identify new types of fraud as they materialize.
As iOS now presents a new vulnerability (which many have overlooked), it becomes clear that security and user privacy play hand-in-hand with fraud protection.